
Qianru Sun
孙倩茹
Associate Professor of Computer Science
Lee Kong Chian Fellow (2021-2023;2025-2027)
School of Computing and Information SystemsSingapore Management University
Contact:
qianrusun "at" smu DOT edu DOT sg80 Stamford Rd, Singapore, 178902
Experiences
Since 2019, I have been working in the School of Computing and Information Systems (SCIS), at Singapore Management University (SMU). Here is my faculty profile. Before that, I was a research fellow working with Prof. Tat-Seng Chua at the National University of Singapore and Prof.Dr. Bernt Schiele at the MPI for Informatics, focusing on interesting machine learning problems such as few-shot learning, meta-learning and continual learning and their implementations on computer vision tasks. From 2016 to 2018, I held the Lise Meitner Award Fellowship and worked with Prof.Dr. Bernt Schiele and Prof. Dr. Mario Fritz at the MPI for Informatics, working on basic computer vision tasks such as image classification and generation. I got my Ph.D. degree from Peking University in 2016. My thesis was advised by Prof. Hong Liu, and the topic is human action recognition in videos. In 2014, I visited the research group of Prof. Tatsuya Harada at the University of Tokyo, working on an interesting task of human anomalous action detection in surveillance videos.
News
Ph.D. Students

2018 - 2022
(with Bernt Schiele)
MPI for Informatics
Now: Asst Prof at UIUC lyy[at]illinois.edu







Master Students

Jan 2020-Dec 2021
SMU

Jan 2022-Nov 2022
SMU

Jan 2022-Dec 2024
SMU
Research Fellows/Assistants

Jan 2020-Dec 2020
Research Assistant
Beijing Jiaotong University

Nov 2019-May 2021
Research Assistant
Hefei University of Technology

Aug 2020-Dec 2020
Research Student
SMU

Aug 2020-Mar 2021
Research Assistant
SMU


Jun 2021-May 2022
Visiting
Jilin University

Aug 2021-Dec 2021
Research Student
SMU

Nov 2021-Oct 2022
Research Assistant
Nanjing University of Science and Technology

Nov 2021-Oct 2022
Visiting
(with Ee-Peng Lim)
Hunan University

Jan 2022-May 2022
Research Assistant
SMU

Sep 2022-Sep 2023
Research Assistant
Zhejiang University

Oct 2022-Oct 2023
Visiting
Shanghai Jiao Tong University

Mar 2023-Feb 2024
Postdoc
SMU
Mar 2023-July 2023
Research Engineer
SMU

Oct 2023-Oct 2024
Visiting PhD Student
Nanjing University of Science and Technology

Oct 2023-Oct 2024
Visiting PhD Student
Harbin Institute of Technology

Oct 2023-Oct 2024
Research Assistant
SMU

Jan 2025-July 2025
Research Engineer
SMU

Jan 2025-July 2025
Visiting Student
Nanjing University of Science and Technology
Publications [Venues]
2025
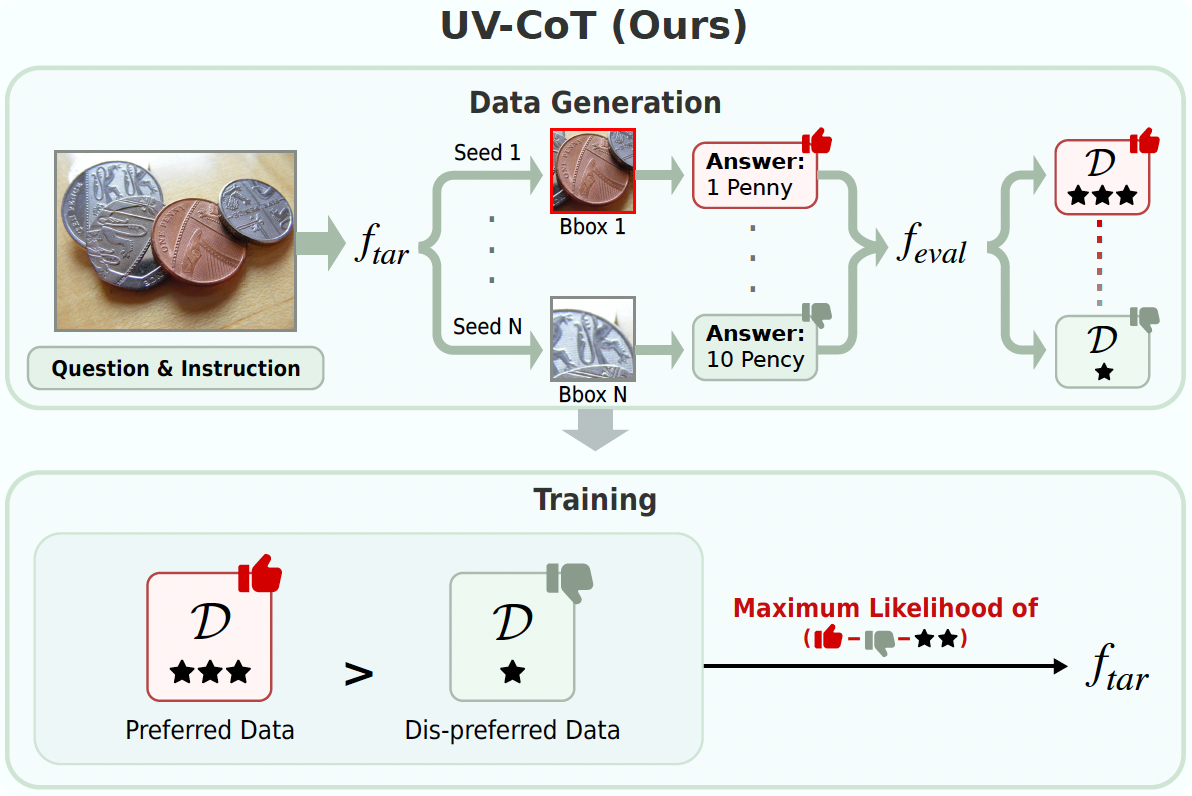
|
Unsupervised Visual Chain-of-Thought Reasoning via Preference Optimization Kesen Zhao, Beier Zhu, Qianru Sun, and Hanwang Zhang International Conference on Computer Vision 2025, ICCV'25. [paper] Chain-of-thought (CoT) reasoning greatly improves the interpretability and problem-solving abilities of multimodal large language models (MLLMs). However, existing approaches are focused on text CoT, limiting their ability to leverage visual cues. Visual CoT remains underexplored, and the only work is based on supervised fine-tuning (SFT) that relies on extensive labeled bounding-box data and is hard to generalize to unseen cases. In this paper, we introduce Unsupervised Visual CoT (UV-CoT), a novel framework for image-level CoT reasoning via preference optimization. UV-CoT performs preference comparisons between model-generated bounding boxes (one is preferred and the other is dis-preferred), eliminating the need for bounding-box annotations. We get such preference data by introducing an automatic data generation pipeline. Given an image, our target MLLM (e.g., LLaVA-1.5-7B) generates seed bounding boxes using a template prompt and then answers the question using each bounded region as input. An evaluator MLLM (e.g., OmniLLM-12B) ranks the responses, and these rankings serve as supervision to train the target MLLM with UV-CoT by minimizing negative log-likelihood losses. By emulating human perception--identifying key regions and reasoning based on them--UV-CoT can improve visual comprehension, particularly in spatial reasoning tasks where textual descriptions alone fall short. Our experiments on six datasets demonstrate the superiority of UV-CoT, compared to the state-of-the-art textual and visual CoT methods. Our zero-shot testing on three unseen datasets shows the strong generalization of UV-CoT. |
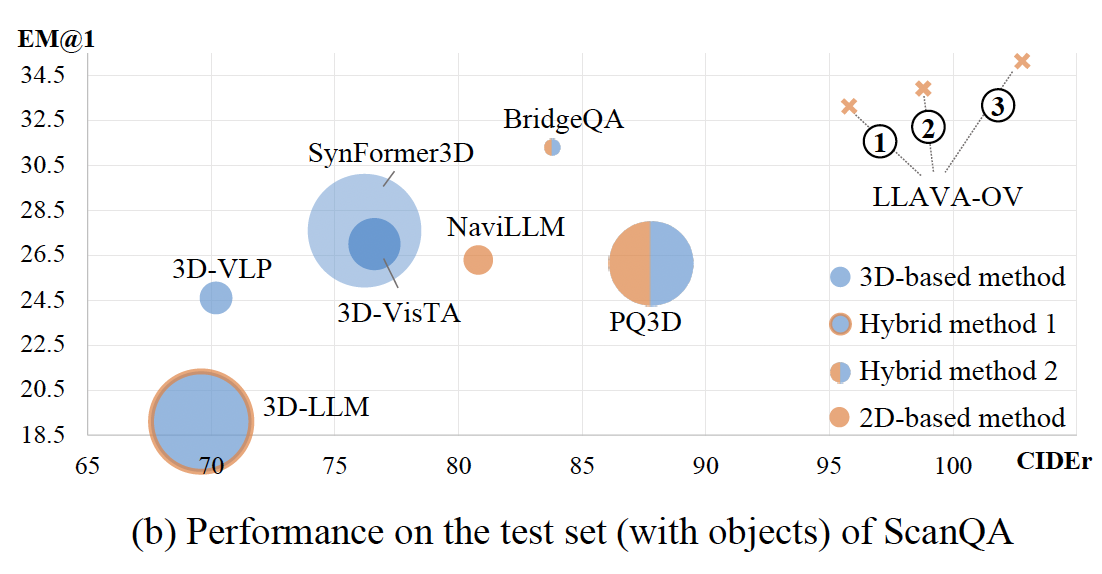
|
3D Question Answering via only 2D Vision-Language Models Fengyun Wang, Sicheng Yu, Jiawei Wu, Jinhui Tang, Hanwang Zhang, and Qianru Sun Forty-second International Conference on Machine Learning, ICML'25. [paper] Large vision-language models (LVLMs) have significantly advanced numerous fields. In this work, we explore how to harness their potential to address 3D scene understanding tasks, using 3D question answering (3D-QA) as a representative example. Due to the limited training data in 3D, we do not train LVLMs but infer in a zero-shot manner. Specifically, we sample 2D views from a 3D point cloud and feed them into 2D models to answer a given question. When the 2D model is chosen, e.g., LLAVA-OV, the quality of sampled views matters the most. We propose cdViews, a novel approach to automatically selecting critical and diverse Views for 3D-QA. cdViews consists of two key components: viewSelector prioritizing critical views based on their potential to provide answer-specific information, and viewNMS enhancing diversity by removing redundant views based on spatial overlap. We evaluate cdViews on the widely-used ScanQA and SQA benchmarks, demonstrating that it achieves state-of-the-art performance in 3D-QA while relying solely on 2D models without fine-tuning. These findings support our belief that 2D LVLMs are currently the most effective alternative (of the resource-intensive 3D LVLMs) for addressing 3D tasks. |
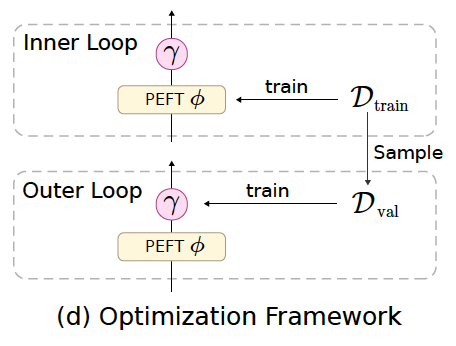
|
Meta-Learning Hyperparameters for Foundation Model Adaptation in Remote-Sensing Imagery Zichen Tian, Yaoyao Liu, and Qianru Sun The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2025, CVPR'25. [paper] Training large foundation models of remote-sensing (RS) images is almost impossible due to the limited and long-tailed data problems. Fine-tuning natural image pre-trained models on RS images is a straightforward solution. To reduce computational costs and improve performance on tail classes, existing methods apply parameter-efficient fine-tuning (PEFT) techniques, such as LoRA and AdaptFormer. However, we observe that fixed hyperparameters -- such as intra-layer positions, layer depth, and scaling factors, can considerably hinder PEFT performance, as fine-tuning on RS images proves highly sensitive to these settings. To address this, we propose MetaPEFT, a method incorporating adaptive scalers that dynamically adjust module influence during fine-tuning. MetaPEFT dynamically adjusts three key factors of PEFT on RS images: module insertion, layer selection, and module-wise learning rates, which collectively control the influence of PEFT modules across the network. We conduct extensive experiments on three transfer-learning scenarios and five datasets. The results show that MetaPEFT achieves state-of-the-art performance in cross-spectral adaptation, requiring only a small amount of trainable parameters and improving tail-class accuracy significantly. |
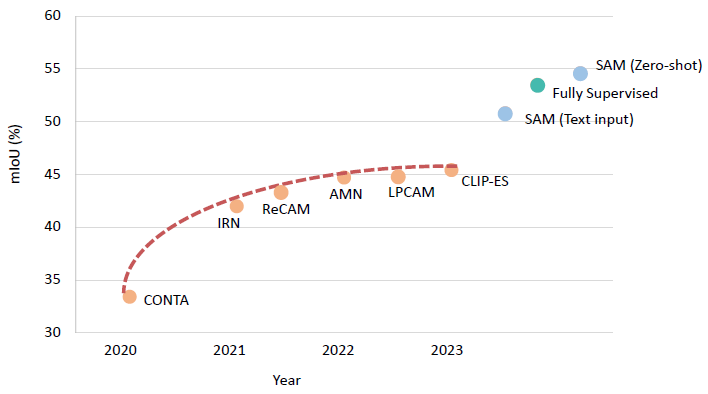
|
Weakly-Supervised Semantic Segmentation with Image-Level Labels: from Traditional Models to Foundation Models Zhaozheng Chen and Qianru Sun ACM Computing Surveys, 2025 [data] [paper]
The rapid development of deep learning has driven significant progress in image semantic segmentation—a fundamental task in computer vision. Semantic segmentation algorithms often depend on the availability of pixel-level labels (i.e., masks of objects), which are expensive, time-consuming, and labor-intensive. Weakly-supervised semantic segmentation (WSSS) is an effective solution to avoid such labeling. It utilizes only partial or incomplete annotations and provides a cost-effective alternative to fully-supervised semantic segmentation. In this journal, our focus is on the WSSS with image-level labels, which is the most challenging form of WSSS. Our work has two parts. First, we conduct a comprehensive survey on traditional methods, primarily focusing on those presented at premier research conferences. We categorize them into four groups based on where their methods operate: pixel-wise, image-wise, cross-image, and external data. Second, we investigate the applicability of visual foundation models, such as the Segment Anything Model (SAM), in the context of WSSS. We scrutinize SAM in two intriguing scenarios: text prompting and zero-shot learning. We provide insights into the potential and challenges of deploying visual foundational models for WSSS, facilitating future developments in this exciting research area. |
|
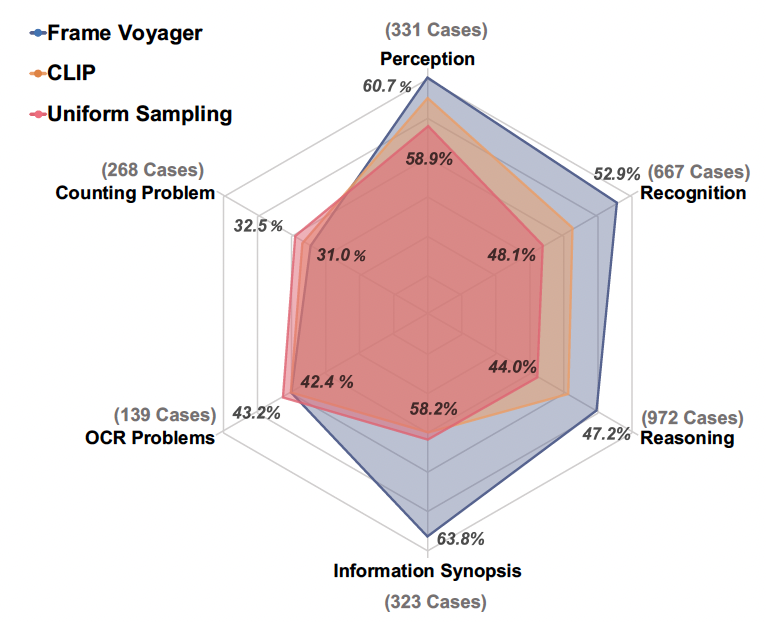
Frame-Voyager: Learning to Query Frames for Video Large Language Models Sicheng Yu, Chengkai Jin,, Jiawei Wu, Hao Zhang, and Qianru Sun The Thirteenth International Conference on Learning Representations, ICLR'25. [paper] Video Large Language Models (Video-LLMs) have made remarkable progress in video understanding tasks. However, they are constrained by the maximum length of input tokens, making it impractical to input entire videos. Existing frame selection approaches, such as uniform frame sampling and text-frame retrieval, fail to account for the information density variations in the videos or the complex instructions in the tasks, leading to sub-optimal performance. In this paper, we propose Frame-Voyager that learns to query informative frame combinations, based on the given textual queries in the task. To train Frame-Voyager, we introduce a new data collection and labeling pipeline, by ranking frame combinations using a pre-trained Video-LLM. Given a video of M frames, we traverse its T-frame combinations, feed them into a Video-LLM, and rank them based on Video-LLM's prediction losses. Using this ranking as supervision, we train Frame-Voyager to query the frame combinations with lower losses. In experiments, we evaluate Frame-Voyager on four Video Question Answering benchmarks by plugging it into two different Video-LLMs. The experimental results demonstrate that Frame-Voyager achieves impressive results in all settings, highlighting its potential as a plug-and-play solution for Video-LLMs. |
|
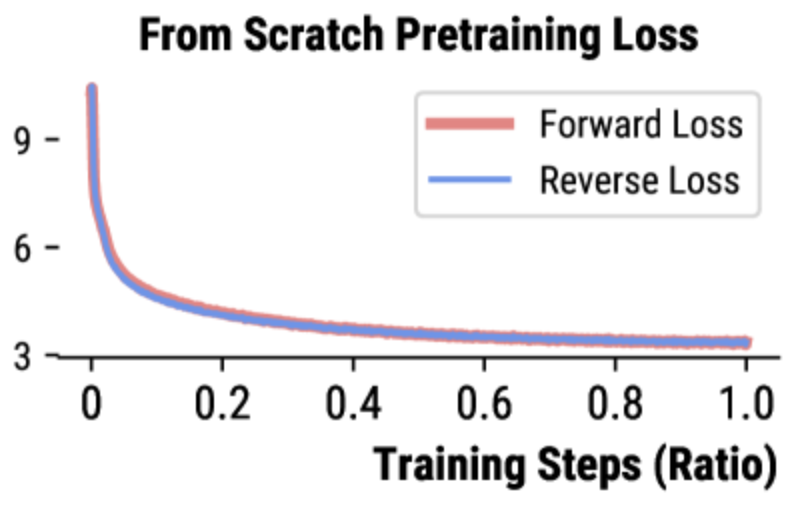
Reverse Modeling in Large Language Models Sicheng Yu, Xu Yuanchen, Cunxiao Du,, Qianru Sun, Hao Zhang, and Jiawei Wu The 2025 Annual Conference of the Nations of the Americas Chapter of the ACL, NAACL'25. [paper] Humans are accustomed to reading and writing in a forward manner, and this natural bias extends to text understanding in auto-regressive large language models (LLMs). This paper investigates whether LLMs, like humans, struggle with reverse modeling, specifically with reversed text inputs. We found that publicly available pre-trained LLMs cannot understand such inputs. However, LLMs trained from scratch with both forward and reverse texts can understand them equally well during inference. Our case study shows that different-content texts result in different losses if input (to LLMs) in different directions---some get lower losses for forward while some for reverse. This leads us to a simple and nice solution for data selection based on the loss differences between forward and reverse directions. Using our selected data in continued pretraining can boost LLMs' performance by a large margin for the task of Massive Multitask Language Understanding. |
2024
|
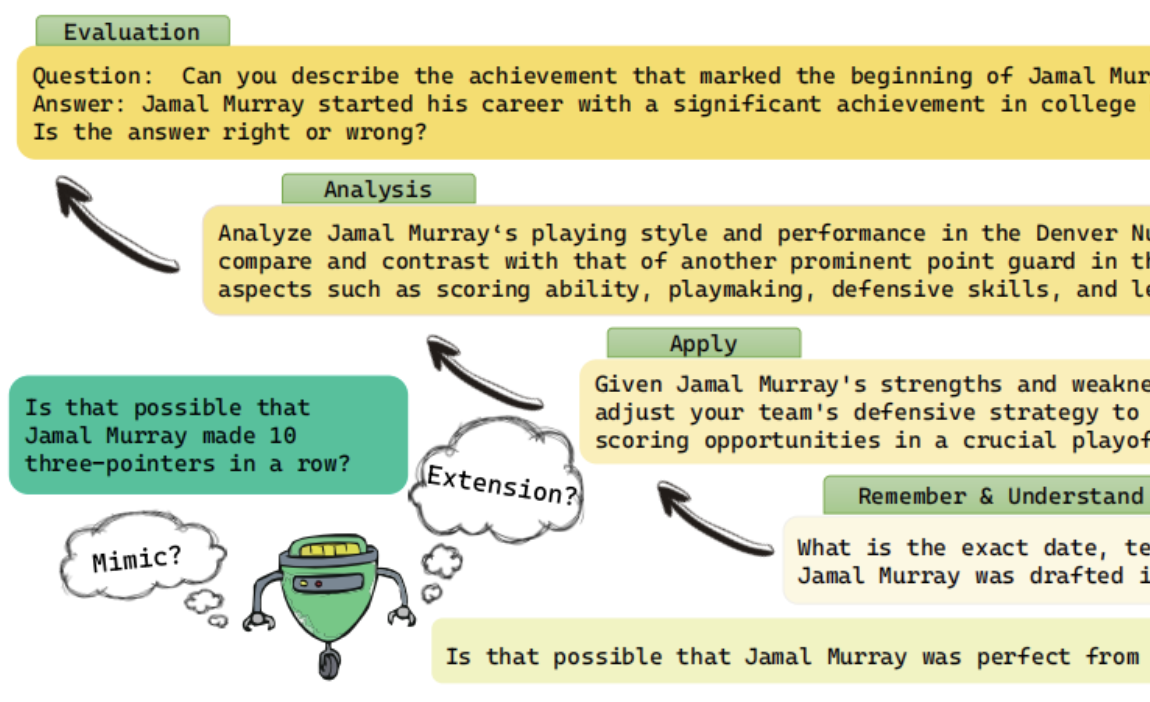
Automating Dataset Updates Towards Reliable and Timely Evaluation of Large Language Models Jiahao Ying, Yixin Cao, Yushi Bai, Qianru Sun, Bo Wang, Wei Tang, Zhaojun Ding, Yizhe Yang, Xuanjing Huang, Shuicheng Yan Conference on Neural Information Processing Systems, NeurIPS '24 (Datasets Track). [data] [paper]
Large language models (LLMs) have achieved impressive performance across various natural language benchmarks, prompting a continual need to curate more difficult datasets for larger LLMs, which is costly and time-consuming. In this paper, we propose to automate dataset updating and provide systematical analysis regarding its effectiveness in dealing with benchmark leakage issue, difficulty control, and stability. Thus, once current benchmark has been mastered or leaked, we can update it for timely and reliable evaluation. There are two updating strategies: 1) mimicking strategy to generate similar samples based on original data, preserving stylistic and contextual essence, and 2) extending strategy that further expands existing samples at varying cognitive levels by adapting Bloom’s taxonomy of educational objectives. Extensive experiments on updated MMLU and BIG-Bench demonstrate the stability of the proposed strategies and find that the mimicking strategy can effectively alleviate issues of overestimation from benchmark leakage. In cases where the efficient mimicking strategy fails, our extending strategy still shows promising results. Additionally, by controlling the difficulty, we can better discern the models’ performance and enable fine-grained analysis — neither too difficult nor too easy an exam can fairly judge students’ learning status. To the best of our knowledge, we are the first to automate updating benchmarks for reliable and timely evaluation. |
|
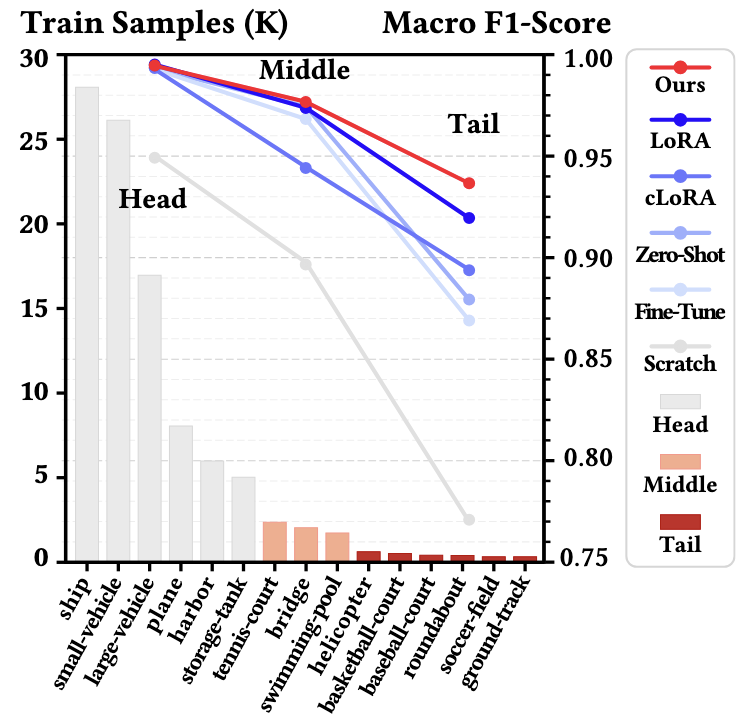
Learning De-Biased Representations for Remote-Sensing Imagery Zicheng Tian, Zhaozheng Chen and Qianru Sun Conference on Neural Information Processing Systems, NeurIPS '24. [paper] [code]
Remote sensing (RS) imagery, requiring specialized satellites to collect and being difficult to annotate, suffers from data scarcity and class imbalance in certain spectrums. Due to data scarcity, training any large-scale RS models from scratch is unrealistic, and the alternative is to transfer pre-trained models by fine-tuning or a more data-efficient method LoRA. Due to class imbalance, transferred models exhibit strong bias, where features of the major class dominate over those of the minor class. In this paper, we propose debLoRA---a generic training approach that works with any LoRA variants to yield debiased features. It is an unsupervised learning approach that can diversify minor class features based on the shared attributes with major classes, where the attributes are obtained by a simple step of clustering. |
|
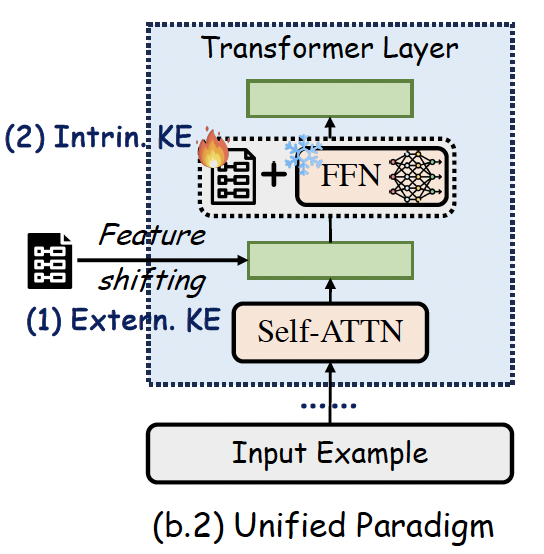
Towards Unified Multimodal Editing with Enhanced Knowledge Collaboration Kaihang Pan, Zhaoyu Fan, Juncheng Li, , and Qianru Sun Conference on Neural Information Processing Systems, NeurIPS '24. (Spotlight) [paper] [code]
The swift advancement in Multimodal LLMs (MLLMs) also presents significant challenges for effective knowledge editing. Current methods, including intrinsic knowledge editing and external knowledge resorting, each possess strengths and weaknesses, struggling to balance the desired properties of reliability, generality, and locality when applied to MLLMs. In this paper, we propose UniKE, a novel multimodal editing method that establishes a unified perspective and paradigm for intrinsic knowledge editing and external knowledge resorting. Both types of knowledge are conceptualized as vectorized key-value memories, with the corresponding editing processes resembling the assimilation and accommodation phases of human cognition, conducted at the same semantic levels. Within such a unified framework, we further promote knowledge collaboration by disentangling the knowledge representations into the semantic and truthfulness spaces. |

|
Unified Generative and Discriminative Training for Multi-modal Large Language Models Wei Chow, Juncheng Li, Kaihang Pan, , and Qianru Sun Conference on Neural Information Processing Systems, NeurIPS '24. [paper] [code]
Vision-Language Models (VLMs) have been trained under two predominant paradigms. Generative training has enabled Multimodal Large Language Models (MLLMs) to tackle various complex tasks, yet issues such as hallucinations and weak object discrimination persist. Discriminative training, exemplified by models like CLIP, excels in zero-shot image-text classification and retrieval, yet struggles with complex scenarios requiring fine-grained semantic differentiation. This paper addresses these challenges by proposing a unified approach that integrates the strengths of both paradigms. Considering interleaved image-text sequences as the general format of input samples, we introduce a structure-induced training strategy that imposes semantic relationships between input samples and the MLLM’s hidden state. This approach enhances the MLLM’s ability to capture global semantics and distinguish fine-grained semantics. By leveraging dynamic sequence alignment within the Dynamic Time Warping framework and integrating a novel kernel for fine-grained semantic differentiation, our method effectively balances generative and discriminative tasks. |
|
Few-shot Learner Parameterization by Diffusion Time-steps Zhongqi Yue, Pan Zhou, Richang Hong, Hanwang Zhang, and Qianru Sun The IEEE/CVF Computer Vision and Pattern Recognition Conference, CVPR '24. [paper] [code]
Even when using large multi-modal foundation models, few-shot learning is still challenging---if there is no proper inductive bias, it is nearly impossible to keep the nuanced class attributes while removing the visually prominent attributes that spuriously correlate with class labels. To this end, we find an inductive bias that the time-steps of a Diffusion Model (DM) can isolate the nuanced class attributes, i.e., as the forward diffusion adds noise to an image at each time-step, nuanced attributes are usually lost at an earlier time-step than the spurious attributes that are visually prominent. Building on this, we propose Time-step Few-shot (TiF) learner. We train class-specific low-rank adapters for a text-conditioned DM to make up for the lost attributes, such that images can be accurately reconstructed from their noisy ones given a prompt. Hence, at a small time-step, the adapter and prompt are essentially a parameterization of only the nuanced class attributes. For a test image, we can use the parameterization to only extract the nuanced class attributes for classification. TiF learner significantly outperforms OpenCLIP and its adapters on a variety of fine-grained and customized few-shot learning tasks. |
|
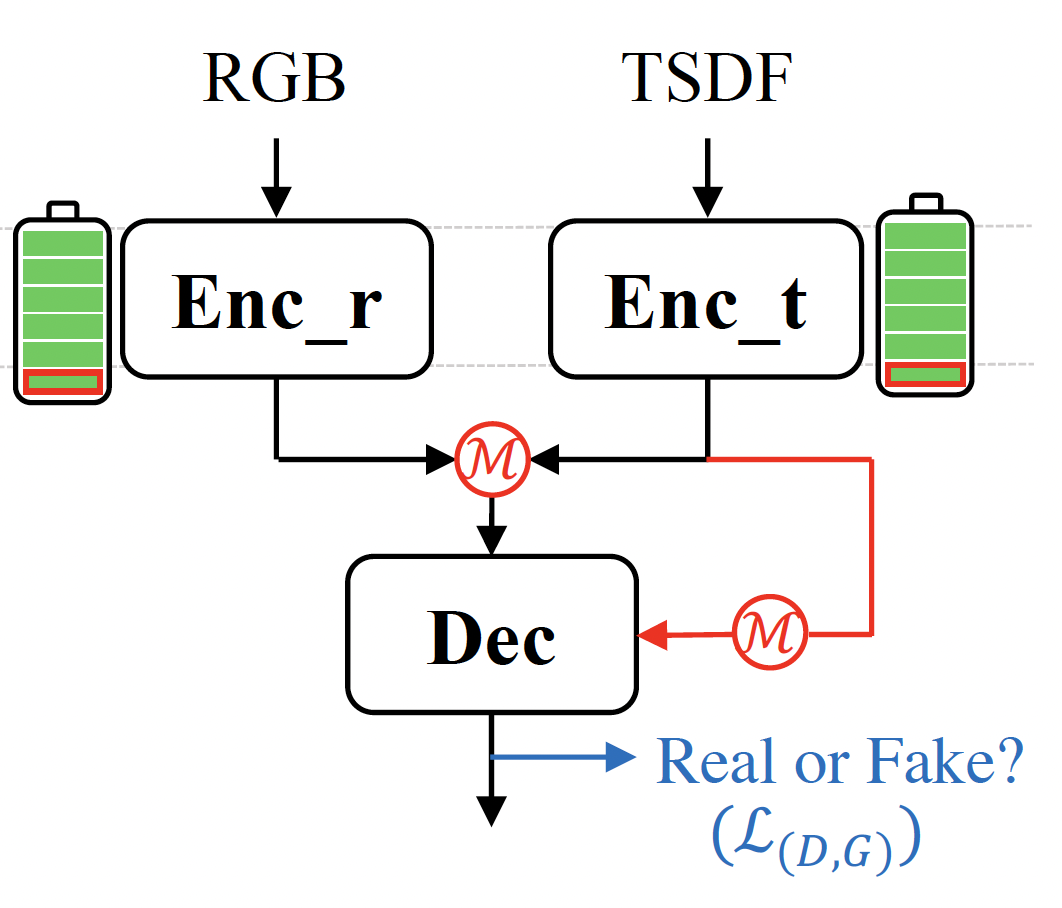
Unleashing Network Potentials for Semantic Scene Completion Fengyun Wang, Qianru Sun, Dong Zhang, and Jinhui Tang The IEEE/CVF Computer Vision and Pattern Recognition Conference, CVPR '24. [paper] [code]
Semantic scene completion (SSC) aims to predict complete 3D voxel occupancy and semantics from a single-view RGB-D image, and recent SSC methods commonly adopt multi-modal inputs. However, our investigation reveals two limitations: ineffective feature learning from single modalities and overfitting to limited datasets. To address these issues, this paper proposes a novel SSC framework - Potential Unleashing Network (PUNet) - with a fresh perspective of optimizing gradient updates. The proposed PUNet introduces two core modules: a cross-modal modulation enabling the interdependence of gradient flows between modalities, and a customized adversarial training scheme leveraging dynamic gradient competition. Specifically, the cross-modal modulation adaptively re-calibrates the features to better excite representation potentials from each single modality. The adversarial training employs a minimax game of evolving gradients, with customized guidance to strengthen the generator's perception of visual fidelity from both geometric completeness and semantic correctness. Extensive experimental results demonstrate that PUNet outperforms state-of-the-art SSC methods by a large margin, providing a promising direction for improving the effectiveness and generalization of SSC methods. |
|
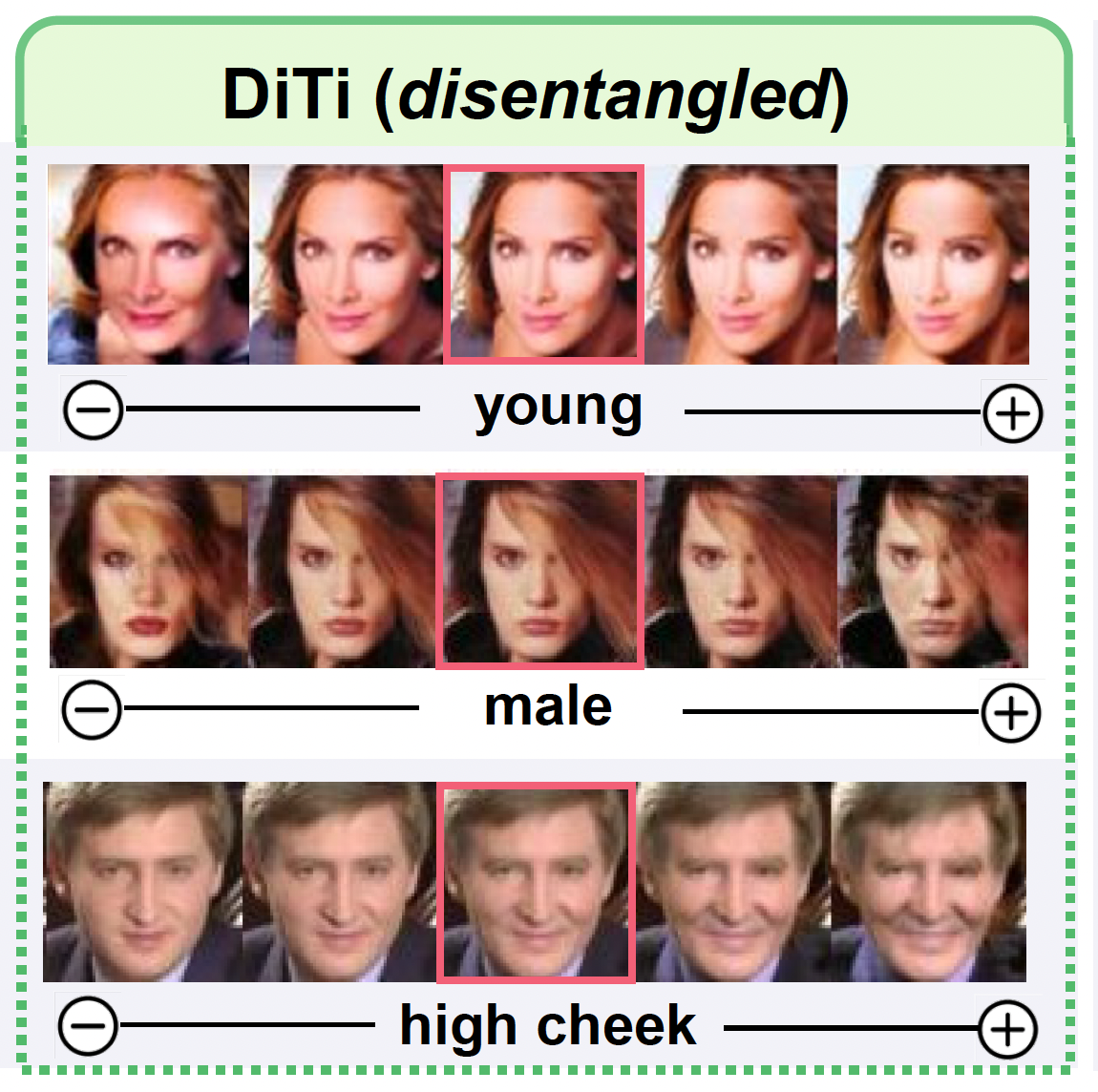
Exploring Diffusion Time-steps for Unsupervised Representation Learning Zhongqi Yue, Jiankun Wang, Qianru Sun, Lei Ji, Eric I-Chao Chang, and Hanwang Zhang The Twelfth International Conference on Learning Representations, ICLR '24. [paper] [code]
Representation learning is all about discovering the hidden modular attributes that generate the data faithfully. We explore the potential of Denoising Diffusion Probabilistic Model (DM) in unsupervised learning of the modular attributes. We build a theoretical framework that connects the diffusion time-steps and the hidden attributes, which serves as an effective inductive bias for unsupervised learning. Specifically, the forward diffusion process incrementally adds Gaussian noise to samples at each time-step, which essentially collapses different samples into similar ones by losing attributes, e.g., fine-grained attributes such as texture are lost with less noise added (i.e., early time-steps), while coarse-grained ones such as shape are lost by adding more noise (i.e., late time-steps). To disentangle the modular attributes, at each time-step t, we learn a t-specific feature to compensate for the newly lost attribute, and the set of all {1,...,t}-specific features, corresponding to the cumulative set of lost attributes, are trained to make up for the reconstruction error of a pre-trained DM at time-step t. On CelebA, FFHQ, and Bedroom datasets, the learned feature significantly improves attribute classification and enables faithful counterfactual generation, e.g., interpolating only one specified attribute between two images, validating the disentanglement quality. |
|
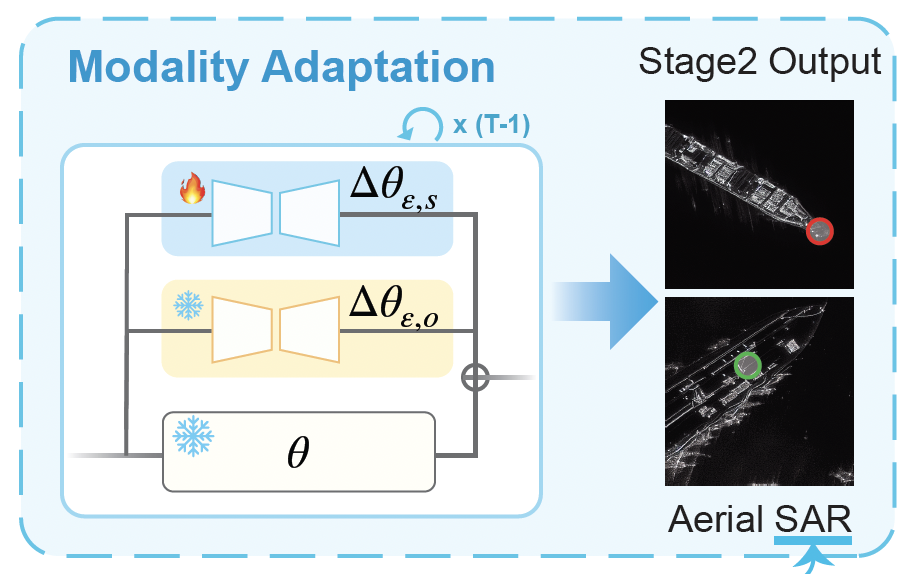
Non-Visible Light Data Synthesis and Application: A Case Study for Synthetic Aperture Radar Imagery Zichen Tian, Zhaozheng Chen, and Qianru Sun ArXiv 2311.17486, 2024. [pre-print] [code]
We explore the "hidden" ability of large-scale pre-trained image generation models, such as Stable Diffusion and Imagen, in non-visible light domains, taking Synthetic Aperture Radar (SAR) data for a case study. Due to the inherent challenges in capturing satellite data, acquiring ample SAR training samples is infeasible. For instance, for a particular category of ship in the open sea, we can collect only few-shot SAR images which are too limited to derive effective ship recognition models. If large-scale models pre-trained with regular images can be adapted to generating novel SAR images, the problem is solved. In preliminary study, we found that fine-tuning these models with few-shot SAR images is not working, as the models can not capture the two primary differences between SAR and regular images: structure and modality. To address this, we propose a 2-stage low-rank adaptation method, and we call it 2LoRA. In the first stage, the model is adapted using aerial-view regular image data (whose structure matches SAR), followed by the second stage where the base model from the first stage is further adapted using SAR modality data. Particularly in the second stage, we introduce a novel prototype LoRA (pLoRA), as an improved version of 2LoRA, to resolve the class imbalance problem in SAR datasets. For evaluation, we employ the resulting generation model to synthesize additional SAR data. This augmentation, when integrated into the training process of SAR classification as well as segmentation models, yields notably improved performance for minor classes. |
|
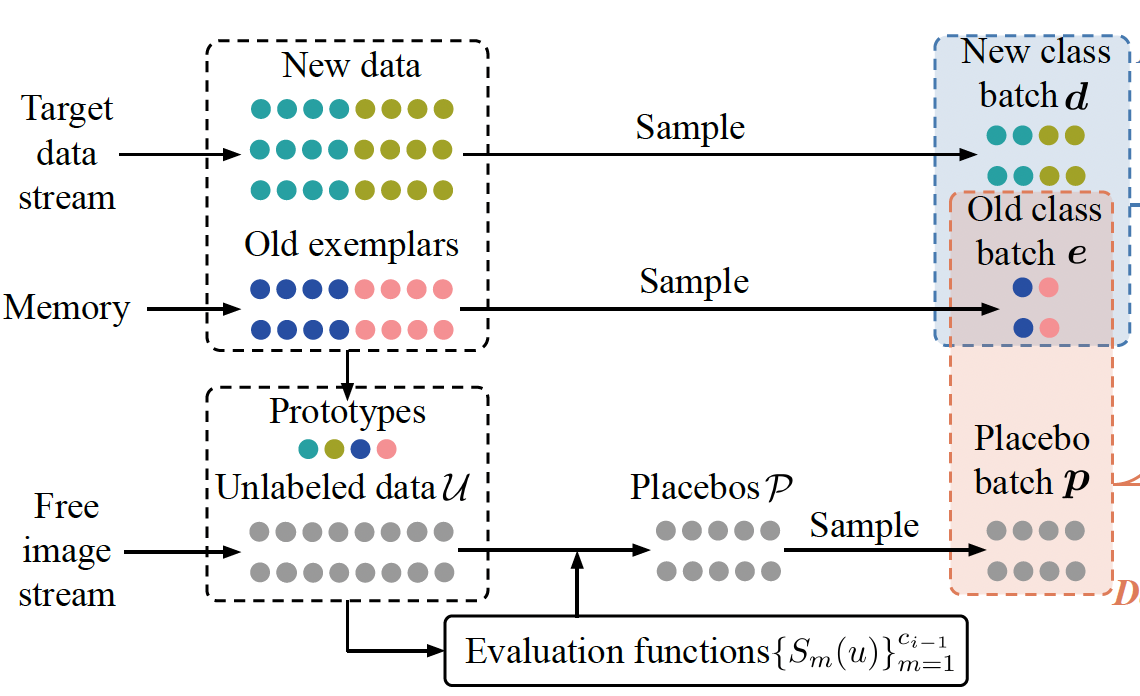
Wakening Past Concepts without Past Data: Class-Incremental Learning from Online Placebos Yaoyao Liu, Yingying Li, Bernt Schiele, and Qianru Sun 2024 IEEE/CVF Winter Conference on Applications of Computer Vision, WACV '24. [paper] [code]
Not forgetting old class knowledge is a key challenge for class-incremental learning (CIL) when the model continuously adapts to new classes. A common technique to address this is knowledge distillation (KD), which penalizes prediction inconsistencies between old and new models. Such prediction is made with almost new class data, as old class data is extremely scarce due to the strict memory limitation in CIL. In this paper, we take a deep dive into KD losses and find that "using new class data for KD" not only hinders the model adaption (for learning new classes) but also results in low efficiency for preserving old class knowledge. We address this by "using the placebos of old classes for KD", where the placebos are chosen from a free image stream, such as Google Images, in an automatical and economical fashion. To this end, we train an online placebo selection policy to quickly evaluate the quality of streaming images (good or bad placebos) and use only good ones for one-time feed-forward computation of KD. We formulate the policy training process as an online Markov Decision Process (MDP), and introduce an online learning algorithm to solve this MDP problem without causing much computation costs. In experiments, we show that our method 1) is surprisingly effective even when there is no class overlap between placebos and original old class data, 2) does not require any additional supervision or memory budget, and 3) significantly outperforms a number of top-performing CIL methods, in particular when using lower memory budgets for old class exemplars, e.g., five exemplars per class. |
2023
|
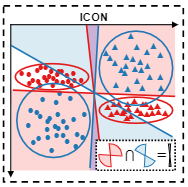
Make the U in UDA Matter: Invariant Consistency Learning for Unsupervised Domain Adaptation Zhongqi Yue, Qianru Sun, and Hanwang Zhang 2023 Conference on Neural Information Processing Systems, NeurIPS '23. [paper] [code]
Domain Adaptation (DA) is always challenged by the spurious correlation between domain-invariant features (e.g., class identity) and domain-specific features (e.g., environment) that do not generalize to the target domain. Unfortunately, even enriched with additional unsupervised target domains, existing Unsupervised DA (UDA) methods still suffer from it. This is because the source domain supervision only considers the target domain samples as auxiliary data (e.g., by pseudo-labeling), yet the inherent distribution in the target domain—where the valuable de-correlation clues hide—is disregarded. We propose to make the U in UDA matter by giving equal status to the two domains. Specifically, we learn an invariant classifier whose prediction is simultaneously consistent with the labels in the source domain and clusters in the target domain, hence the spurious correlation inconsistent in the target domain is removed. We dub our approach “Invariant CONsistency learning” (ICON). Extensive experiments show that ICON achieves state-of-the-art performance on the classic UDA benchmarks: OFFICE-HOME and VISDA-2017, and outperforms all the conventional methods on the challenging WILDS2.0 benchmark. |
|
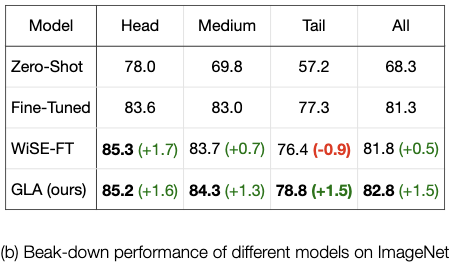
Generalized Logit Adjustment: Calibrating Fine-tuned Models by Removing Label Bias in Foundation Models Beier Zhu, Kaihua Tang, Qianru Sun, and Hanwang Zhang 2023 Conference on Neural Information Processing Systems, NeurIPS '23. [paper] [code]
Foundation models like CLIP allow zero-shot transfer on various tasks without additional training data. Yet, the zero-shot performance is less competitive than a fully supervised one. Thus, to enhance the performance, fine-tuning and ensembling are also commonly adopted to better fit the downstream tasks. However, we argue that such prior work has overlooked the inherent biases in foundation models. Due to the highly imbalanced Web-scale training set, these foundation models are inevitably skewed toward frequent semantics, and thus the subsequent fine-tuning or ensembling is still biased. In this study, we systematically examine the biases in foundation models and demonstrate the efficacy of our proposed Generalized Logit Adjustment (GLA) method. Note that bias estimation in foundation models is challenging, as most pre-train data cannot be explicitly accessed like in traditional long-tailed classification tasks. To this end, GLA has an optimization-based bias estimation approach for debiasing foundation models. As our work resolves a fundamental flaw in the pre-training, the proposed GLA demonstrates significant improvements across a diverse range of tasks: it achieves 1.5 pp accuracy gains on ImageNet, an large average improvement (1.4-4.6 pp) on 11 few-shot datasets, 2.4 pp gains on long-tailed classification. |
|
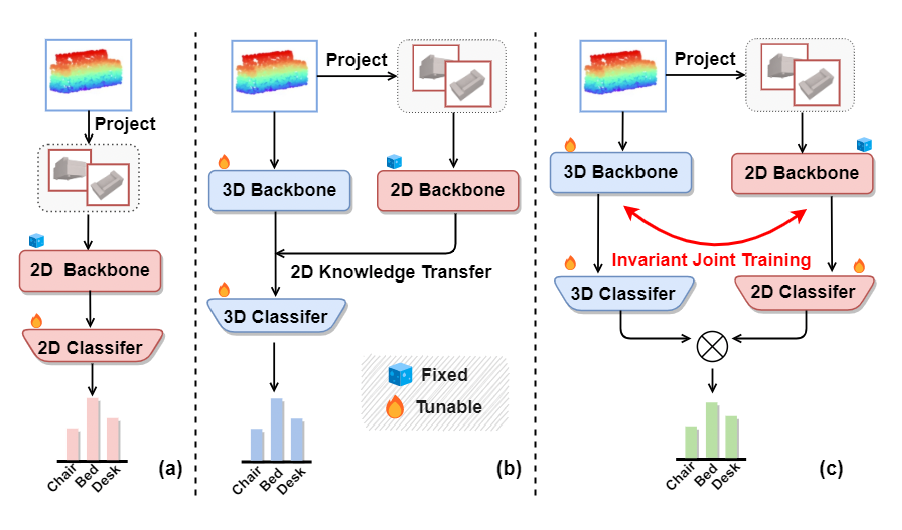
Invariant Training 2D-3D Joint Hard Samples for Few-Shot Point Cloud Recognition Xuanyu Yi, Jiajun Deng, Qianru Sun, Xian-Sheng Hua, Joo-Hwee Lim, and Hanwang Zhang 2023 International Conference on Computer Vision, ICCV '23. [paper] [code]
We tackle the data scarcity challenge in few-shot point cloud recognition of 3D objects by using a joint prediction from a conventional 3D model and a well-pretrained 2D model. Surprisingly, such an ensemble, though seems trivial, has hardly been shown effective in recent 2D-3D models. We find out the crux is the less effective training for the “joint hard samples”, which have high confidence prediction on different wrong labels, implying that the 2D and 3D models do not collaborate well. To this end, our proposed invariant training strategy, called INVJOINT, does not only emphasize the training more on the hard samples, but also seeks the invariance between the conflicting 2D and 3D ambiguous predictions. INVJOINT can learn more collaborative 2D and 3D representations for better ensemble. Extensive experiments on 3D shape classification with widely-adopted ModelNet10/40, ScanObjectNN and Toys4K, and shape retrieval with ShapeNet-Core validate the superiority of our INVJOINT. |
|
Semantic Scene Completion with Cleaner Self Fengyun Wang, Dong Zhang, Hanwang Zhang, Jinhui Tang, and Qianru Sun 2023 Conference on Computer Vision and Pattern Recognition, CVPR '23. [paper] [code]
Semantic Scene Completion (SSC) transforms an image of single-view depth and/or RGB 2D pixels into 3D voxels, each of whose semantic labels are predicted. SSC is a well-known ill-posed problem as the prediction model has to “imagine” what is behind the visible surface, which is usually represented by Truncated Signed Distance Function (TSDF). Due to the sensory imperfection of the depth camera, most existing methods based on the noisy TSDF estimated from depth values suffer from 1) incomplete volumetric predictions and 2) confused semantic labels. To this end, we use the ground-truth 3D voxels to generate a perfect visible surface, called TSDF-CAD, and then train a “cleaner” SSC model. As the model is noise-free, it is expected to focus more on the “imagination” of unseen voxels. Then, we propose to distill the intermediate “cleaner” knowledge into another model with noisy TSDF input. In particular, we use the 3D occupancy feature and the semantic relations of the “cleaner self” to supervise the counterparts of the “noisy self” to respectively address the above two incorrect predictions. Experimental results validate that the proposed method improves the noisy counterparts with 3.1% IoU and 2.2% mIoU for measuring scene completion and SSC separately, and also achieves a new state-of-the-art performance on the popular NYU dataset. |
|
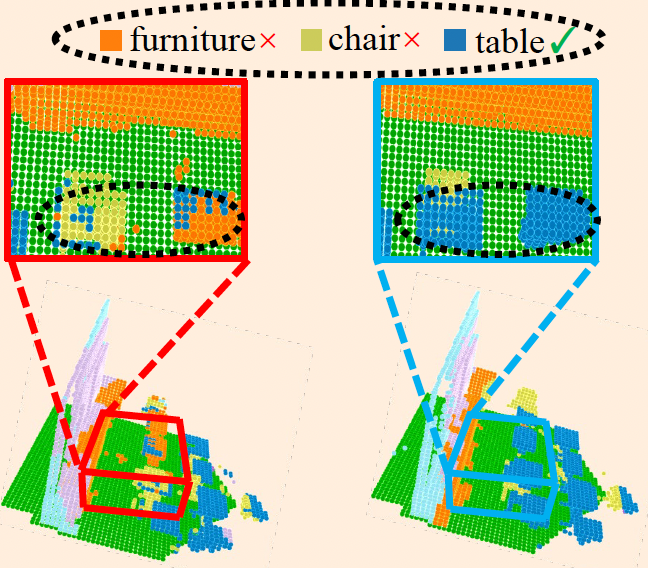
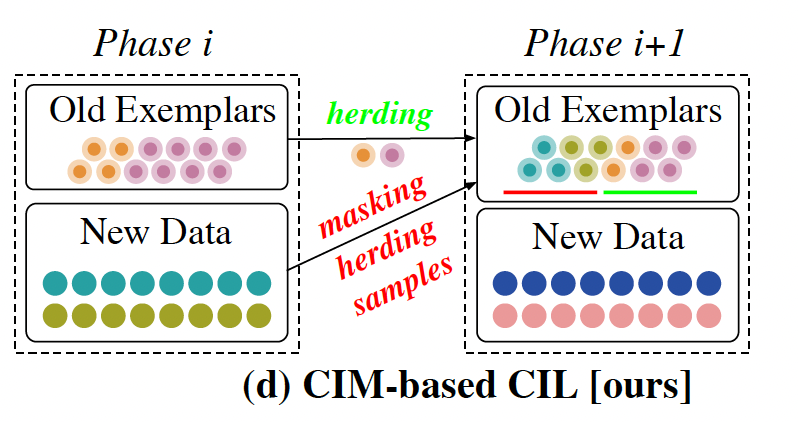
Class-Incremental Exemplar Compression for Class-Incremental Learning Zilin Luo, Yaoyao Liu, Bernt Schiele, Qianru Sun 2023 Conference on Computer Vision and Pattern Recognition, CVPR '23. [paper] [code]
Exemplar-based class-incremental learning (CIL) finetunes the model with all samples of new classes but few-shot exemplars of old classes in each incremental phase, where the "few-shot" abides by the limited memory budget. In this paper, we break this "few-shot" limit based on a simple yet surprisingly effective idea: compressing exemplars by downsampling non-discriminative pixels and saving "many-shot" compressed exemplars in the memory. Without needing any manual annotation, we achieve this compression by generating 0-1 masks on discriminative pixels from class activation maps (CAM). We propose an adaptive mask generation model called class-incremental masking (CIM) to explicitly resolve two difficulties of using CAM: 1) transforming the heatmaps of CAM to 0-1 masks with an arbitrary threshold leads to a trade-off between the coverage on discriminative pixels and the quantity of exemplars, as the total memory is fixed; and 2) optimal thresholds vary for different object classes, which is particularly obvious in the dynamic environment of CIL. We optimize the CIM model alternatively with the conventional CIL model through a bilevel optimization problem. We conduct extensive experiments on high-resolution CIL benchmarks including Food-101, ImageNet-100, and ImageNet-1000, and show that using the compressed exemplars by CIM can achieve a new state-of-the-art CIL accuracy, e.g., 4.8 percentage points higher than FOSTER on 10-Phase ImageNet-1000. |
|
Unbiased Multiple Instance Learning for Weakly Supervised Video Anomaly Detection Hui Lv, Zhongqi Yue, Qianru Sun, Bin Luo, Zhen Cui, and Hanwang Zhang 2023 Conference on Computer Vision and Pattern Recognition, CVPR '23. [paper] [code]
Weakly Supervised Video Anomaly Detection (WSVAD) is challenging because the binary anomaly label is only given on the video level, but the output requires snippet-level predictions. So, Multiple Instance Learning (MIL) is prevailing in WSVAD. However, MIL is notoriously known to suffer from many false alarms because the snippet-level detector is easily biased towards the abnormal snippets with simple context, confused by the normality with the same bias, and missing the anomaly with a different pattern. To this end, we propose a new MIL framework: Unbiased MIL (UMIL), to learn unbiased anomaly features that improve WSVAD. At each MIL training iteration, we use the current detector to divide the samples into two groups with different context biases: the most confident abnormal/normal snippets and the rest ambiguous ones. Then, by seeking the invariant features across the two sample groups, we can remove the variant context biases. |
|
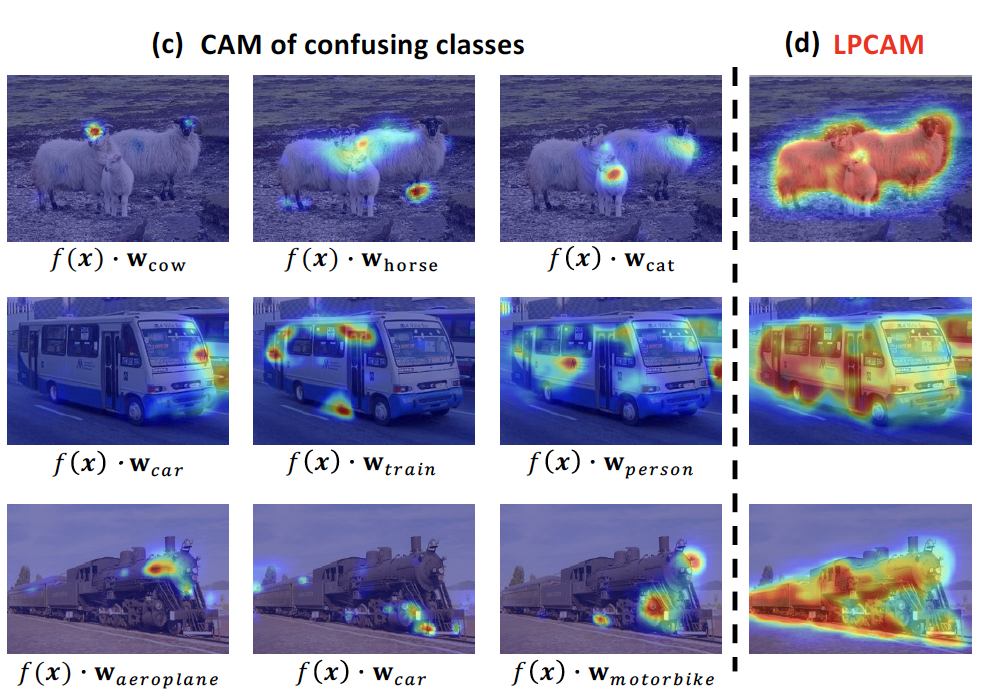
Extracting Class Activation Maps from Non-Discriminative Features as well Zhaozheng Chen and Qianru Sun 2023 Conference on Computer Vision and Pattern Recognition, CVPR '23. [paper] [code]
Extracting class activation maps (CAM) from a classification model often results in poor coverage on foreground objects, i.e., only the discriminative region (e.g., the “head” of “sheep”) is recognized and the rest (e.g., the “leg” of “sheep”) mistakenly as background. The crux behind is that the weight of the classifier (used to compute CAM) captures only the discriminative features of objects. We tackle this by introducing a new computation method for CAM that explicitly captures non-discriminative features as well, thereby expanding CAM to cover whole objects. Specifically, we omit the last pooling layer of the classification model, and perform clustering on all local features of an object class, where “local” means “at a spatial pixel position”. We call the resultant K cluster centers local prototypes - represent local semantics like the “head”, “leg”, and “body” of “sheep”. Given a new image of the class, we compare its unpooled features to every prototype, derive K similarity matrices, and then aggregate them into a heatmap (i.e., our CAM). Our CAM thus captures all local features of the class without discrimination. We evaluate it in the challenging tasks of weakly-supervised semantic segmentation (WSSS), and plug it in multiple state-of-the-art WSSS methods, such as MCTformer and AMN, by simply replacing their original CAM with ours. Our extensive experiments on standard WSSS benchmarks (PASCAL VOC and MS COCO) show the superiority of our method: consistent improvements with little computational overhead. |
|
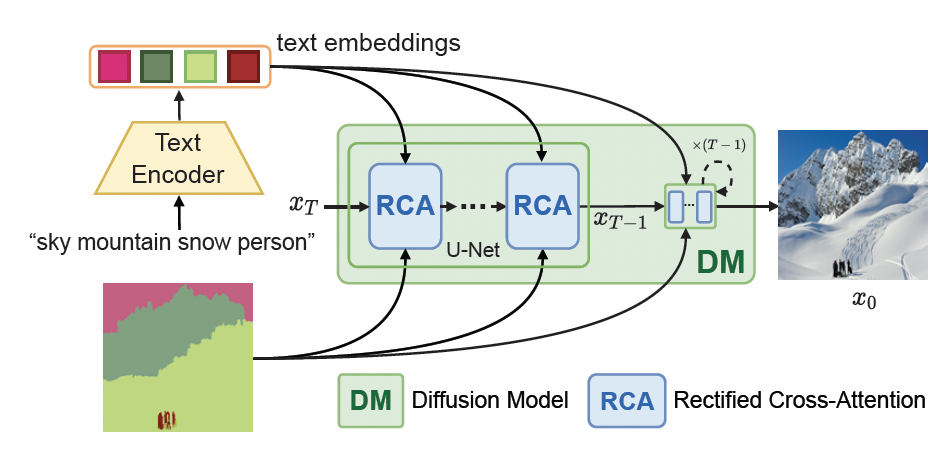
Freestyle Layout-to-Image Synthesis Han Xue, Zhiwu Huang, Qianru Sun, Li Song, and Wenjun Zhang 2023 Conference on Computer Vision and Pattern Recognition, CVPR '23. (Highlight, 2.5%) [paper] [code]
Typical layout-to-image synthesis (LIS) models generate images for a close set of semantic classes, e.g., 182 common objects in COCO-Stuff. In this work, we explore the freestyle capability of the model, i.e., how far can it generate unseen semantics (e.g., classes, attributes, and styles) onto a given layout, and call the task Freestyle LIS (FLIS). Thanks to the development of large-scale pre-trained language-image models, a number of discriminative models (e.g., image classification and object detection) trained on limited base classes are empowered with the ability of unseen class prediction. Inspired by this, we opt to leverage large-scale pre-trained text-to-image diffusion models to achieve the generation of unseen semantics. The key challenge of FLIS is how to enable the diffusion model to synthesize images from a specific layout which very likely violates its pre-learned knowledge, e.g., the model never sees "a unicorn sitting on a bench" during its pre-training. To this end, we introduce a new module called Rectified Cross-Attention (RCA) that can be conveniently plugged in the diffusion model to integrate semantic masks. This "plug-in" is applied in each cross-attention layer of the model to rectify the attention maps between image and text tokens. The key idea of RCA is to enforce each text token to act on the pixels in a specified region, allowing us to freely put a wide variety of semantics from pre-trained knowledge (which is general) onto the given layout (which is specific). |
|
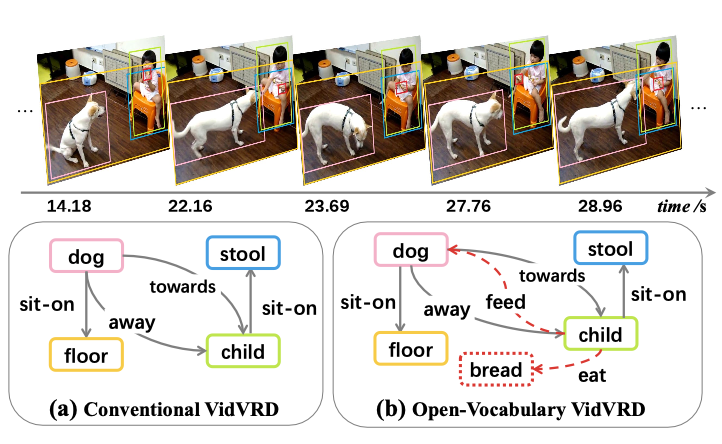
Compositional Prompt Tuning with Motion Cues for Open-vocabulary Video Relation Detection Kaifeng Gao, Long Chen, Hanwang Zhang, Jun Xiao, and Qianru Sun The Eleventh International Conference on Learning Representations, ICLR '23. [paper] [code] [appendix]
Prompt tuning with large-scale pretrained vision-language models empowers open-vocabulary prediction trained on limited base categories, e.g., object classification and detection. In this paper, we propose compositional prompt tuning with motion cues: an extended prompt tuning paradigm for compositional predictions of video data. In particular, we present Relation Prompt (RePro) for Open-vocabulary Video Visual Relation Detection (Open-VidVRD), where conventional prompt tuning is easily biased to certain subject-object combinations and motion patterns. To this end, RePro addresses the two technical challenges of Open-VidVRD: 1) the prompt tokens should respect the two different semantic roles of subject and object, and 2) the tuning should account for the diverse spatiotemporal motion patterns of the subject-object compositions. Our RePro achieves a new state-of-the-art performance on two VidVRD benchmarks of not only the base training object and predicate categories, but also the unseen ones. Extensive ablations also demonstrate the effectiveness of the proposed compositional and multi-mode design of prompt. |
|
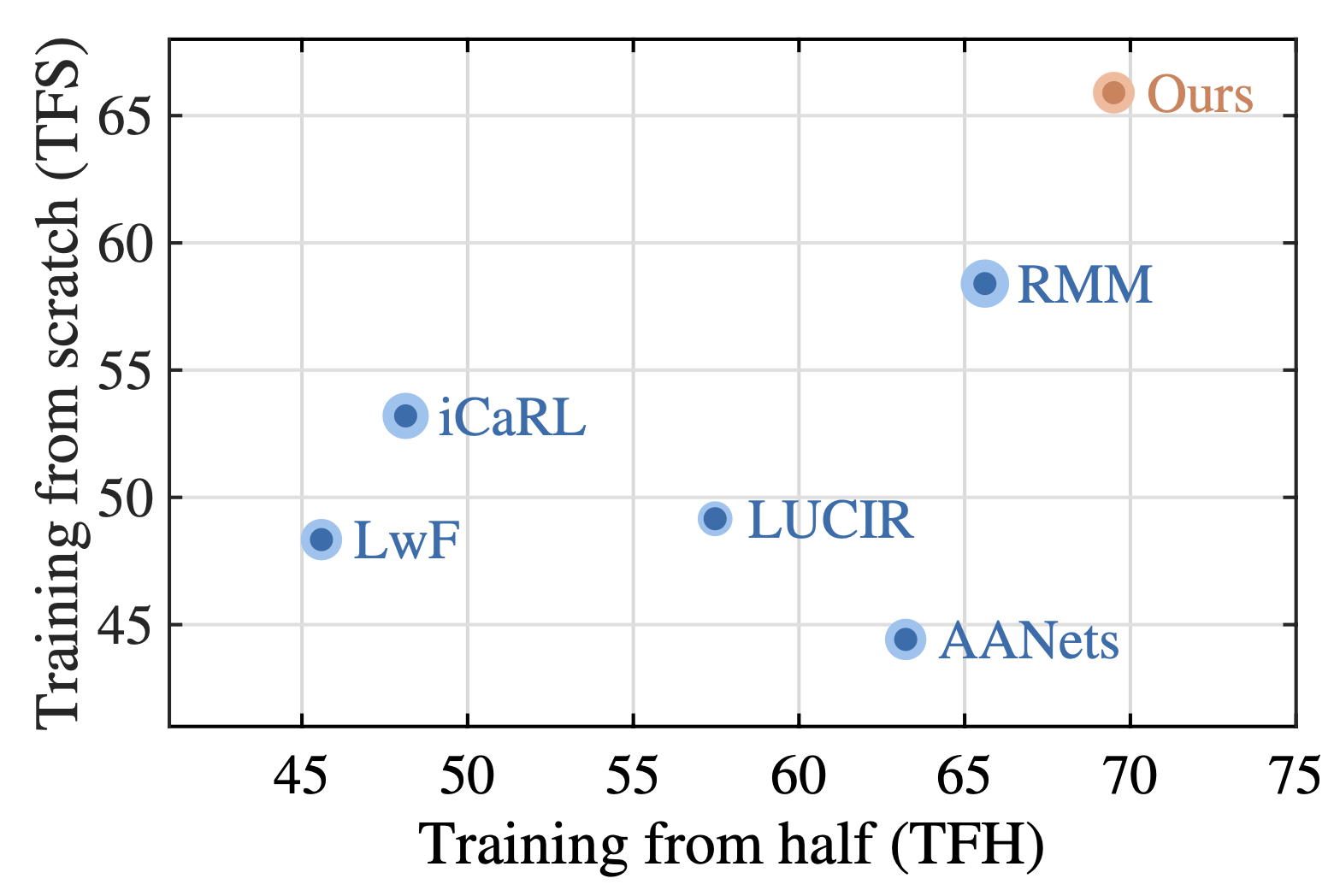
Online Hyperparameter Optimization for Class-Incremental Learning Yaoyao Liu, Yingying Li, Bernt Schiele, and Qianru Sun Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI '23. [paper] [code]
Class-incremental learning (CIL) aims to train a classification model while the number of classes increases phase-by-phase. An inherent challenge of CIL is the stability-plasticity tradeoff, i.e., CIL models should keep stable to retain old knowledge and keep plastic to absorb new knowledge. However, none of the existing CIL models can achieve the optimal tradeoff in different data-receiving settings—where typically the training-from-half (TFH) setting needs more stability, but the training-from-scratch (TFS) needs more plasticity. To this end, we design an online learning method that can adaptively optimize the tradeoff without knowing the setting as a priori. Specifically, we first introduce the key hyperparameters that influence the tradeoff, e.g., knowledge distillation (KD) loss weights, learning rates, and classifier types. Then, we formulate the hyperparameter optimization process as an online Markov Decision Process (MDP) problem and propose a specific algorithm to solve it. We apply local estimated rewards and a classic bandit algorithm Exp3 (Auer et al. 2002) to address the issues when applying online MDP methods to the CIL protocol. Our method consistently improves top-performing CIL methods in both TFH and TFS settings, e.g., boosting the average accuracy of TFH and TFS by 2.2 percentage points on ImageNet-Full. |
2022
|
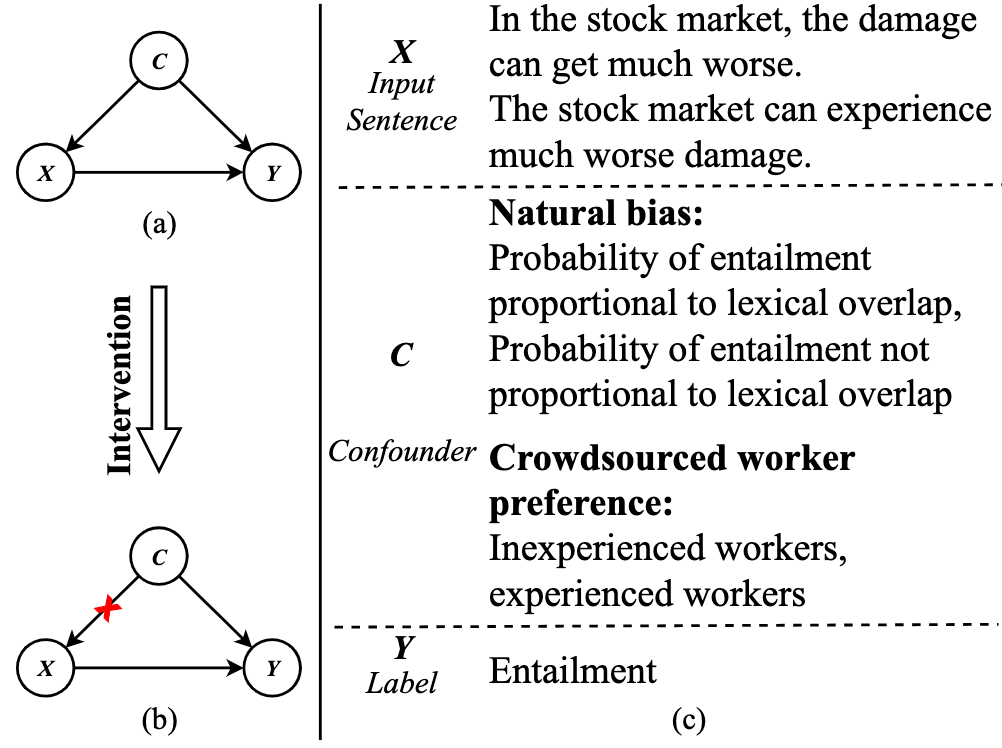
Interventional Training for Out-Of-Distribution Natural Language Understanding Sicheng Yu, Jing Jiang, Hao Zhang, Yulei Niu, Qianru Sun, Lidong Bing The 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP '22. [paper]
Out-of-distribution (OOD) settings are used to measure a model’s performance when the distribution of the test data is different from that of the training data. NLU models are known to suffer in OOD settings (Utama et al., 2020b). We study this issue from the perspective of causality, which sees confounding bias as the reason for models to learn spurious correlations. While a common solution is to perform intervention, existing methods handle only known and single confounder, but in many NLU tasks the confounders can be both unknown and multifactorial. In this paper, we propose a novel interventional training method called Bottom-up Automatic Intervention (BAI) that performs multi-granular intervention with identified multifactorial confounders. Our experiments on three NLU tasks, namely, natural language inference, fact verification and paraphrase identification, show the effectiveness of BAI for tackling OOD settings. |

|
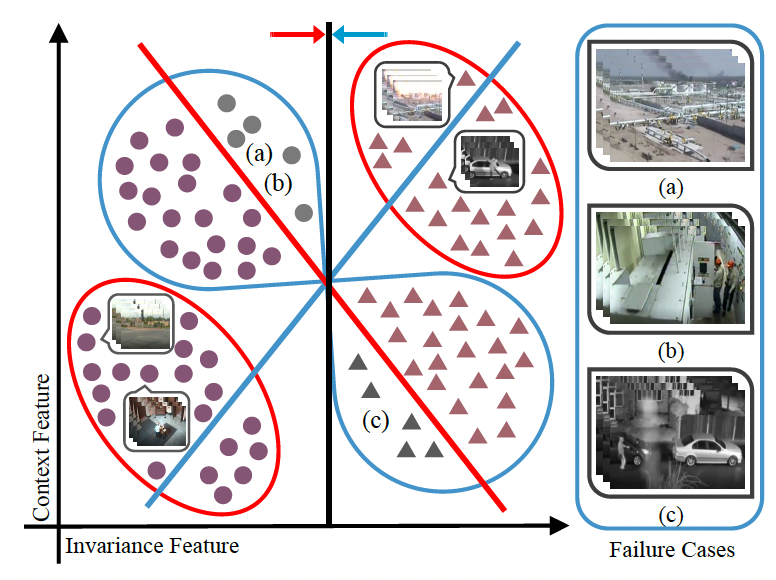
Class Is Invariant to Context and Vice Versa: On Learning Invariance for Out-Of-Distribution Generalization Jiaxin Qi, Kaihua Tang, Qianru Sun, Xian-Sheng Hua, Hanwang Zhang European Conference on Computer Vision 2022, ECCV '22. [paper] [code] [appendix]
Out-Of-Distribution generalization (OOD) is all about learning invariance against environmental changes. If the context in every class is evenly distributed, OOD would be trivial because the context can be easily removed due to an underlying principle: class is invariant to context. However, collecting such a balanced dataset is impractical. Learning on imbalanced data makes the model bias to context and thus hurts OOD. Therefore, the key to OOD is context balance.We argue that the widely adopted assumption in prior work—the context bias can be directly annotated or estimated from biased class prediction—renders the context incomplete or even incorrect. In contrast, we point out the everoverlooked other side of the above principle: context is also invariant to class, which motivates us to consider the classes (which are already labeled) as the varying environments to resolve context bias (without context labels). We implement this idea by minimizing the contrastive loss of intra-class sample similarity while assuring this similarity to be invariant across all classes. On benchmarks with various context biases and domain gaps, we show that a simple re-weighting based classifier equipped with our context estimation achieves state-of-the-art performance. We provide theoretical justifications and source code in Appendix. |
|
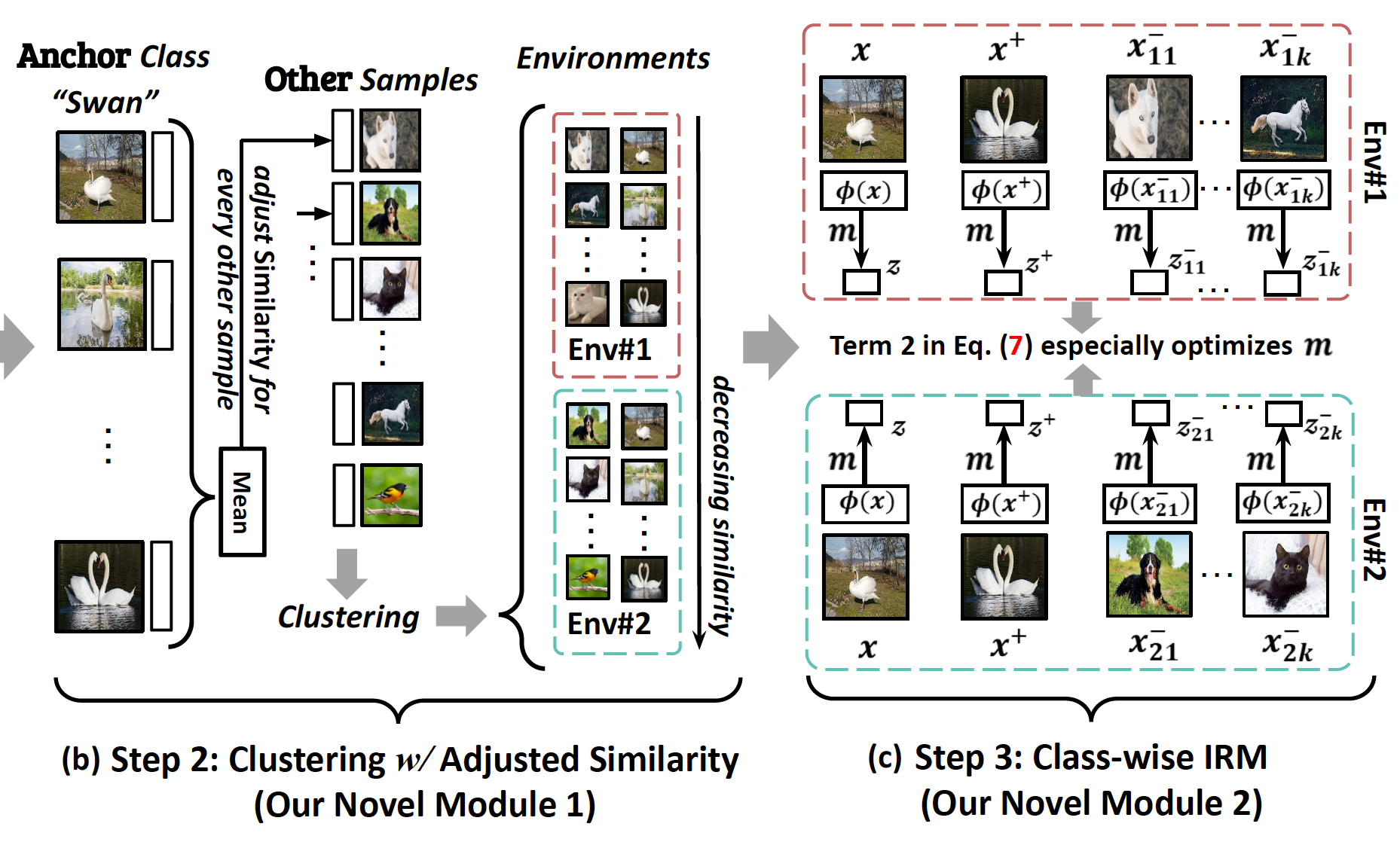
Equivariance and Invariance Inductive Bias for Learning from Insufficient Data Tan Wang, Qianru Sun, Sugiri Pranata, Karlekar Jayashree, Hanwang Zhang European Conference on Computer Vision 2022, ECCV '22. [paper] [code] [appendix]
We are interested in learning robust models from insufficient data, without the need for any externally pre-trained model checkpoints. First, compared to sufficient data, we show why insufficient data renders the model more easily biased to the limited training environments that are usually different from testing. For example, if all the training "swan" samples are "white", the model may wrongly use the "white" environment to represent the intrinsic class "swan". Then, we justify that equivariance inductive bias can retain the class feature while invariance inductive bias can remove the environmental feature, leaving only the class feature that generalizes to any testing environmental changes. To impose them on learning, for equivariance, we demonstrate that any off-the-shelf contrastive-based self-supervised feature learning method can be deployed; for invariance, we propose a class-wise invariant risk minimization (IRM) that efficiently tackles the challenge of missing environmental annotation in conventional IRM. State-of-the-art experimental results on real-world visual benchmarks (NICO and VIPriors ImageNet) validate the great potential of the two inductive biases in reducing training data and parameters significantly. |
|
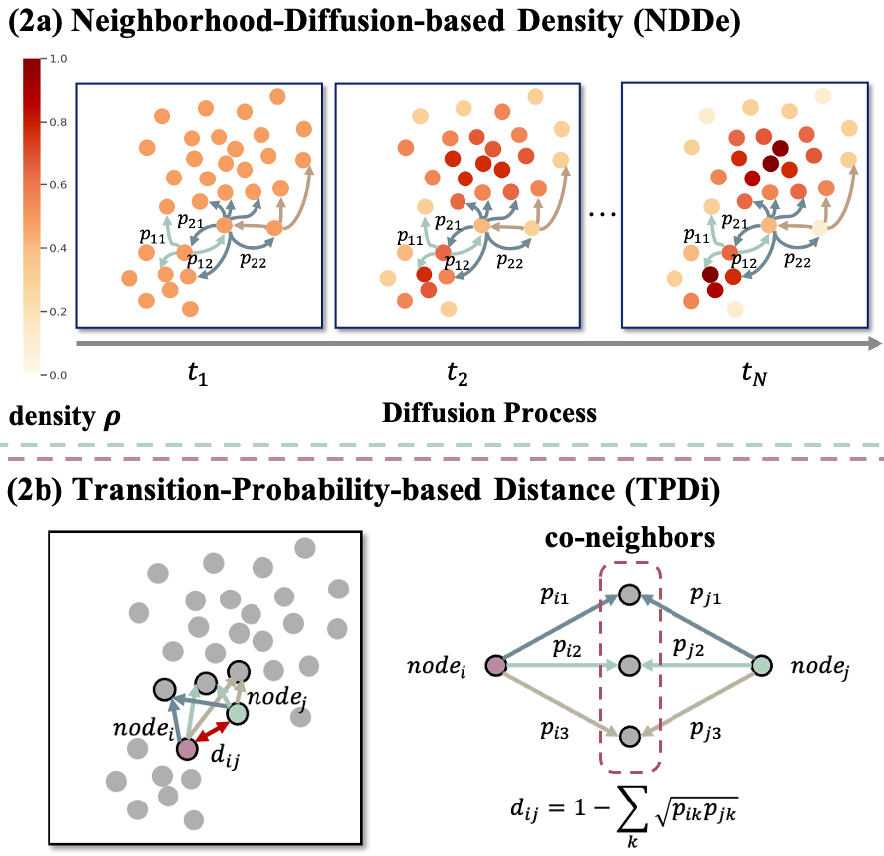
On Mitigating Hard Clusters for Face Clustering Yingjie Chen, Huasong Zhong, Chong Chen, Chen Shen, Jianqiang Huang, Tao Wang, Yun Liang, Qianru Sun European Conference on Computer Vision 2022, ECCV '22. (Oral Presentation, 2.7%) [paper] [code]
Face clustering is a promising way to scale up face recognition systems using large-scale unlabeled face images. It remains challenging to identify small or sparse face image clusters that we call hard clusters, which is caused by the heterogeneity, i.e., high variations in size and sparsity, of the clusters. Consequently, the conventional way of using a uniform threshold (to identify clusters) often leads to a terrible misclassification for the samples that should belong to hard clusters. We tackle this problem by leveraging the neighborhood information of samples and inferring the cluster memberships (of samples) in a probabilistic way. We introduce two novel modules, Neighborhood-Diffusion-based Density (NDDe) and Transition-Probability-based Distance (TPDi), based on which we can simply apply the standard Density Peak Clustering algorithm with a uniform threshold. Our experiments on multiple benchmarks show that each module contributes to the final performance of our method, and by incorporating them into other advanced face clustering methods, these two modules can boost the performance of these methods to a new state-of-the-art. |
|
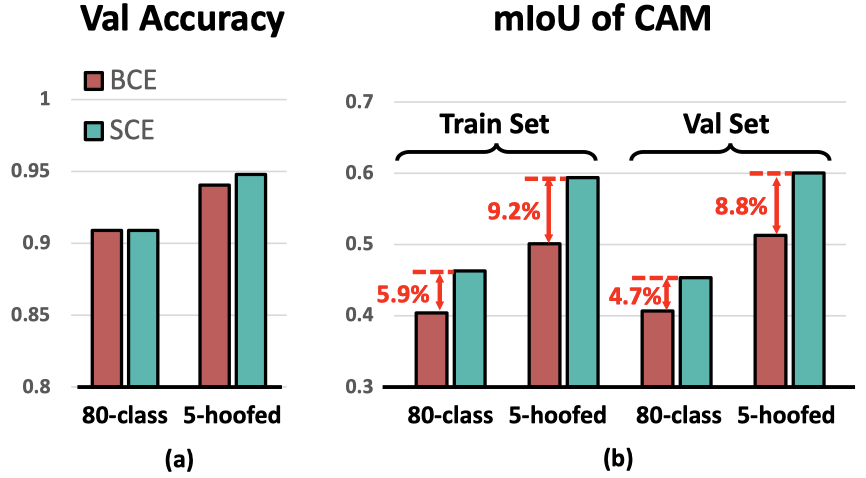
Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation Zhaozheng Chen, Tan Wang, Xiongwei Wu, Xian-Sheng Hua, Hanwang Zhang, Qianru Sun 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR '22. [paper] [code]
Extracting class activation maps (CAM) is arguably the most standard step of generating pseudo masks for weakly supervised semantic segmentation (WSSS). Yet, we find that the crux of the unsatisfactory pseudo masks is the binary cross-entropy loss (BCE) widely used in CAM. Specifically, due to the sum-over-class pooling nature of BCE, each pixel in CAM may be responsive to multiple classes co-occurring in the same receptive field. To this end, we introduce an embarrassingly simple yet surprisingly effective method: Reactivating the converged CAM with BCE by using softmax crossentropy loss (SCE), dubbed ReCAM. Given an image, we use CAM to extract the feature pixels of each single class, and use them with the class label to learn another fully-connected layer (after the backbone) with SCE. Once converged, we extract ReCAM in the same way as in CAM. |

|
Translate-Train Embracing Translationese Artifacts Sicheng Yu, Qianru Sun, Hao Zhang, Jing Jiang Association for Computational Linguistics, ACL '22. [paper] [code]
Translate-train is a general training approach to multilingual tasks. The key idea is to use the translator of the target language to generate training data to mitigate the gap between the source and target languages. However, its performance is often hampered by the artifacts in the translated texts (translationese). We discover that such artifacts have common patterns in different languages and can be modeled by deep learning, and subsequently propose an approach to conduct translate-train using Translationese Embracing the effect of Artifacts (TEA). TEA learns to mitigate such effect on the training data of a source language (whose original and translationese are both available), and applies the learned module to facilitate the inference on the target language. |
|
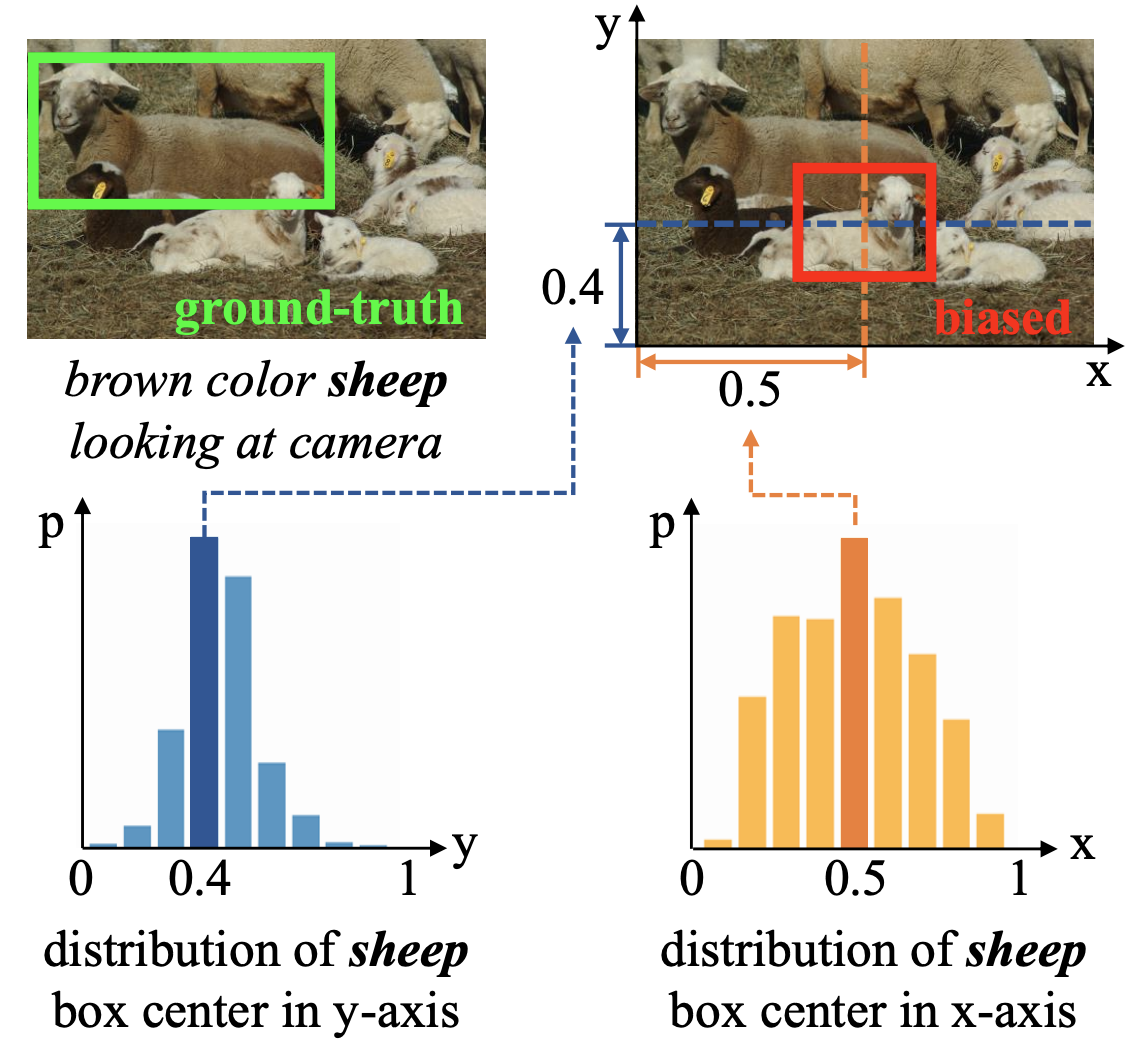
Deconfounded Visual Grounding Jianqiang Huang, Yu Qin, Jiaxin Qi, Qianru Sun, Hanwang Zhang The 36th AAAI Conference on Artificial Intelligence, AAAI '22. (15%) [paper] [code] We focus on the confounding bias between language and location in the visual grounding pipeline, where we find that the bias is the major visual reasoning bottleneck. For example, the grounding process is usually a trivial languagelocation association without visual reasoning, e.g., grounding any language query containing sheep to the nearly central regions, due to that most queries about sheep have groundtruth locations at the image center. First, we frame the visual grounding pipeline into a causal graph, which shows the causalities among image, query, target location and underlying confounder. Through the causal graph, we know how to break the grounding bottleneck: deconfounded visual grounding. Second, to tackle the challenge that the confounder is unobserved in general, we propose a confounder-agnostic approach called: Referring Expression Deconfounder (RED), to remove the confounding bias. Third, we implement RED as a simple language attention, which can be applied in any grounding method. |
2021
|
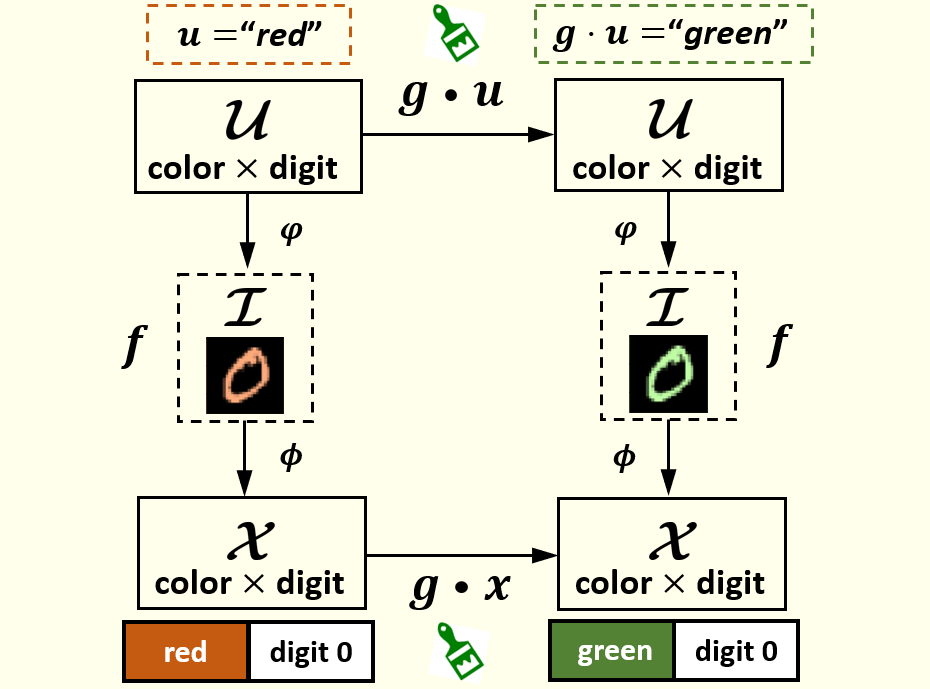
Self-Supervised Learning Disentangled Group Representation as Feature Tan Wang, Zhongqi Yue, Jianqiang Huang, Qianru Sun, Hanwang Zhang 2021 Conference on Neural Information Processing Systems, NeurIPS '21. (Spotlight Presentation, 3%) [paper] [code] A good visual representation is an inference map from observations (images) to features (vectors) that faithfully reflects the hidden modularized generative factors (semantics). In this paper, we formulate the notion of "good" representation from a group-theoretic view using Higgins' definition of disentangled representation, and show that existing Self-Supervised Learning (SSL) only disentangles simple augmentation features such as rotation and colorization, thus unable to modularize the remaining semantics. To break the limitation, we propose an iterative SSL algorithm: Iterative Partition-based Invariant Risk Minimization (IP-IRM), which successfully grounds the abstract semantics and the group acting on them into concrete contrastive learning. At each iteration, IP-IRM first partitions the training samples into two subsets that correspond to an entangled group element. Then, it minimizes a subset-invariant contrastive loss, where the invariance guarantees to disentangle the group element. We prove that IP-IRM converges to a fully disentangled representation and show its effectiveness on various benchmarks. |
|
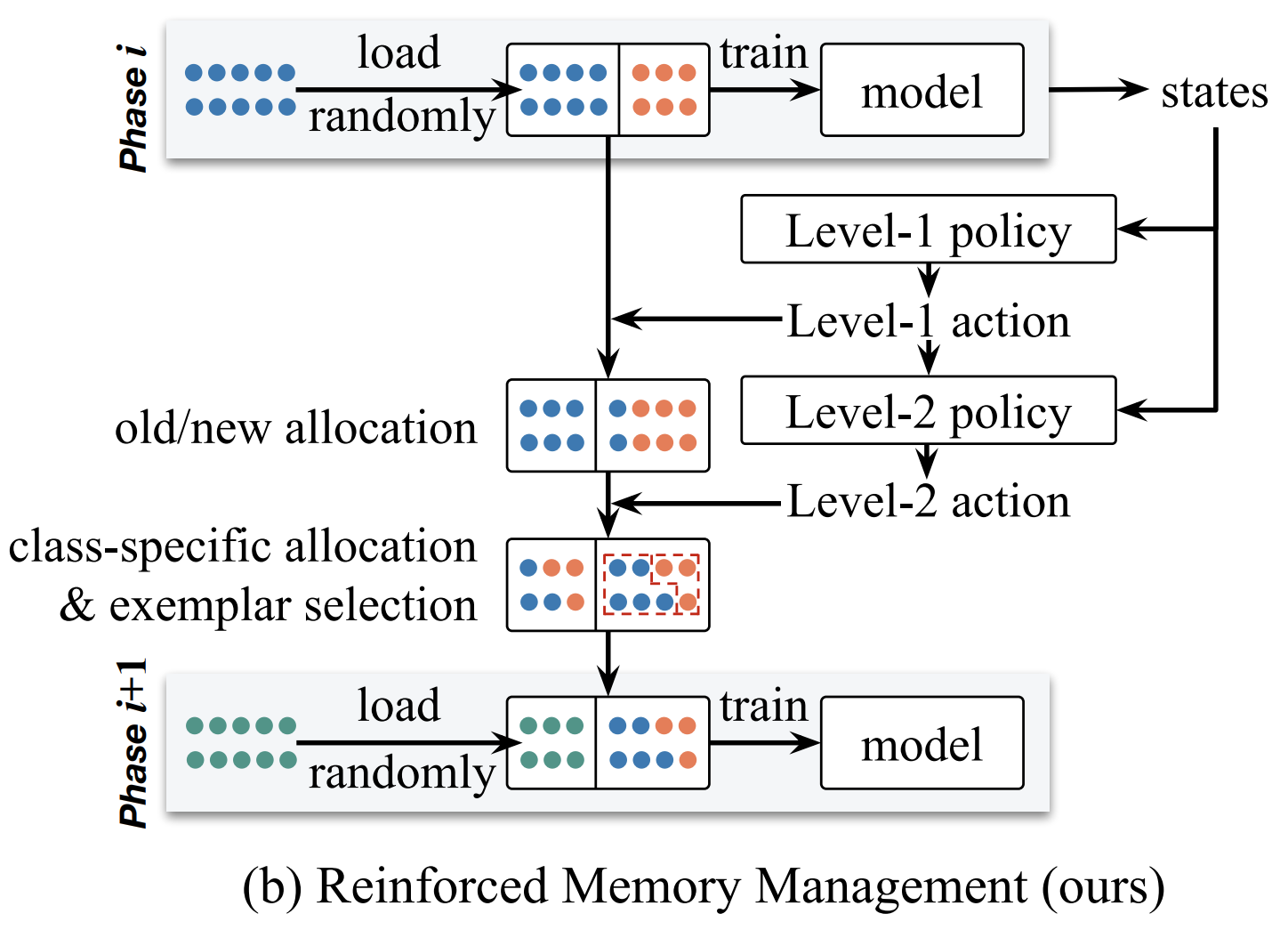
RMM: Reinforced Memory Management for Class-Incremental Learning Yaoyao Liu, Bernt Schiele, Qianru Sun 2021 Conference on Neural Information Processing Systems, NeurIPS '21. [paper] [code] Class-Incremental Learning (CIL) trains classifiers under a strict memory budget: in each incremental phase, learning is done for new data, most of which is abandoned to free space for the next phase. The preserved data are exemplars used for replaying. However, existing methods use a static and ad hoc strategy for memory allocation, which is often sub-optimal. In this work, we propose a dynamic memory management strategy that is optimized for the incremental phases and different object classes. We call our method reinforced memory management (RMM), leveraging reinforcement learning. RMM training is not naturally compatible with CIL as the past, and future data are strictly non-accessible during the incremental phases. We solve this by training the policy function of RMM on pseudo CIL tasks, e.g., the tasks built on the data of the 0-th phase, and then applying it to target tasks. RMM propagates two levels of actions: Level-1 determines how to split the memory between old and new classes, and Level-2 allocates memory for each specific class. In essence, it is an optimizable and general method for memory management that can be used in any replaying-based CIL method. |
|
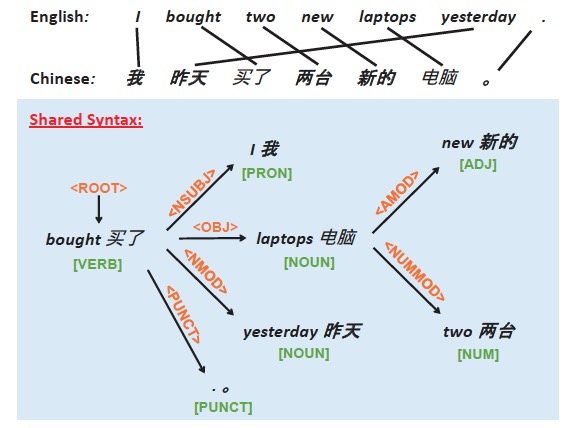
COSY: COunterfactual SYntax for Cross-Lingual Understanding Sicheng Yu, Hao Zhang, Yulei Niu, Qianru Sun, Jing Jiang Association for Computational Linguistics, ACL '21. [paper] Pre-trained multilingual language models, eg, multilingual-BERT, are widely used in cross-lingual tasks, yielding the state-of-the-art performance. However, such models suffer from a large performance gap between source and target languages, especially in the zero-shot setting, where the models are fine-tuned only on English but tested on other languages for the same task. We tackle this issue by incorporating language-agnostic information, specifically, universal syntax such as dependency relations and POS tags, into language models, based on the observation that universal syntax is transferable across different languages. Our approach, named COunterfactual SYntax (COSY), includes the design of SYntax-aware networks as well as a COunterfactual training method to implicitly force the networks to learn not only the semantics but also the syntax. |
|
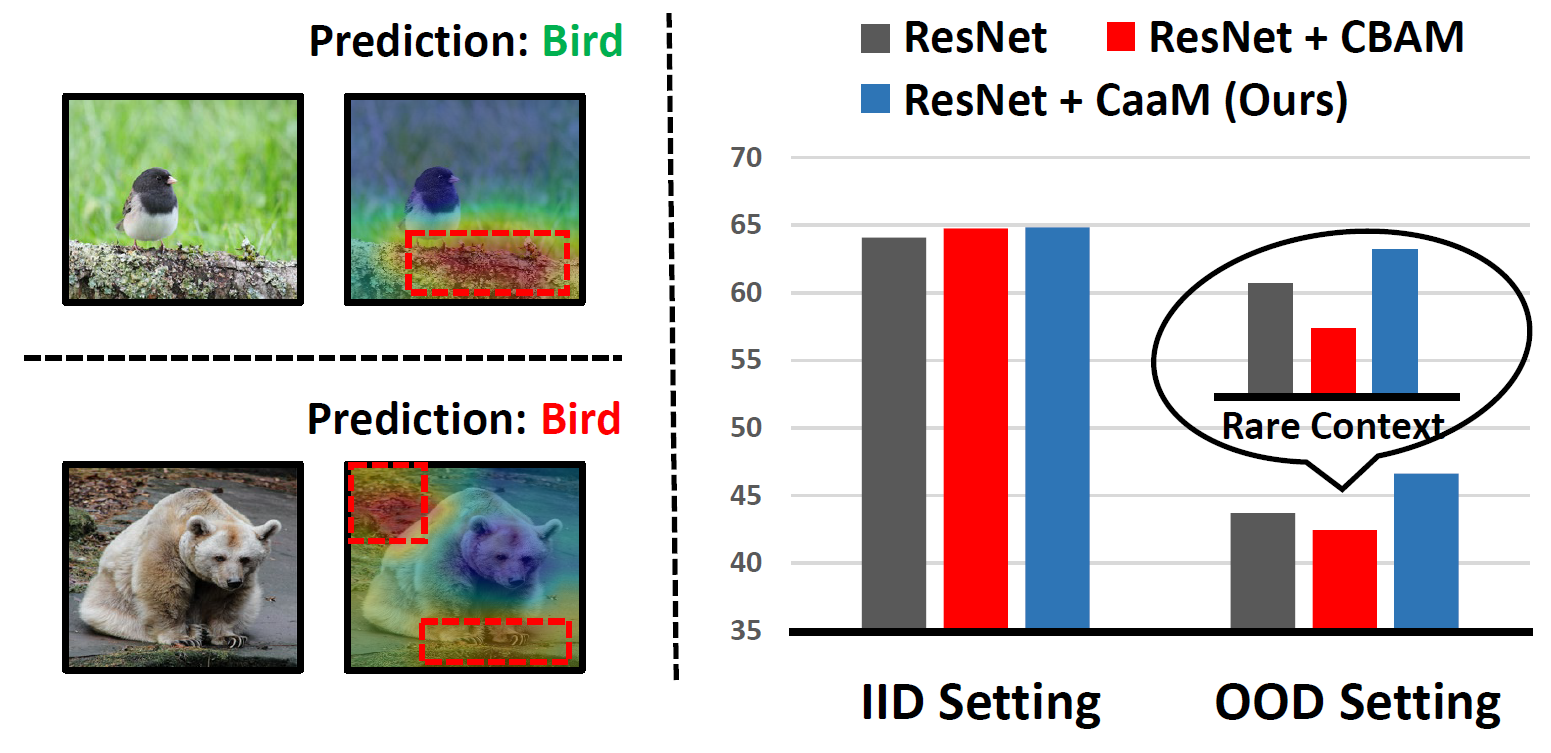
Causal Attention for Unbiased Visual Recognition Tan Wang, Chang Zhou, Qianru Sun, Hanwang Zhang International Conference on Computer Vision, ICCV '21. [paper] [code] Attention module does not always help deep models learn causal features that are robust in any confounding context, e.g., a foreground object feature is invariant to different backgrounds. This is because the confounders trick the attention to capture spurious correlations that benefit the prediction when the training and testing data are IID; while harm the prediction when the data are OOD. The sole fundamental solution to learn causal attention is by causal intervention, which requires additional annotations of the confounders, e.g., a "dog" model is learned within "grass+dog" and "road+dog" respectively, so the "grass" and "road" contexts will no longer confound the "dog" recognition. However, such annotation is not only prohibitively expensive, but also inherently problematic, as the confounders are elusive in nature. In this paper, we propose a causal attention module (CaaM) that self-annotates the confounders in unsupervised fashion. In particular, multiple CaaMs can be stacked and integrated in conventional attention CNN and self-attention Vision Transformer. In OOD settings, deep models with CaaM outperform those without it significantly; even in IID settings, the attention localization is also improved by CaaM, showing a great potential in applications that require robust visual saliency. |
|
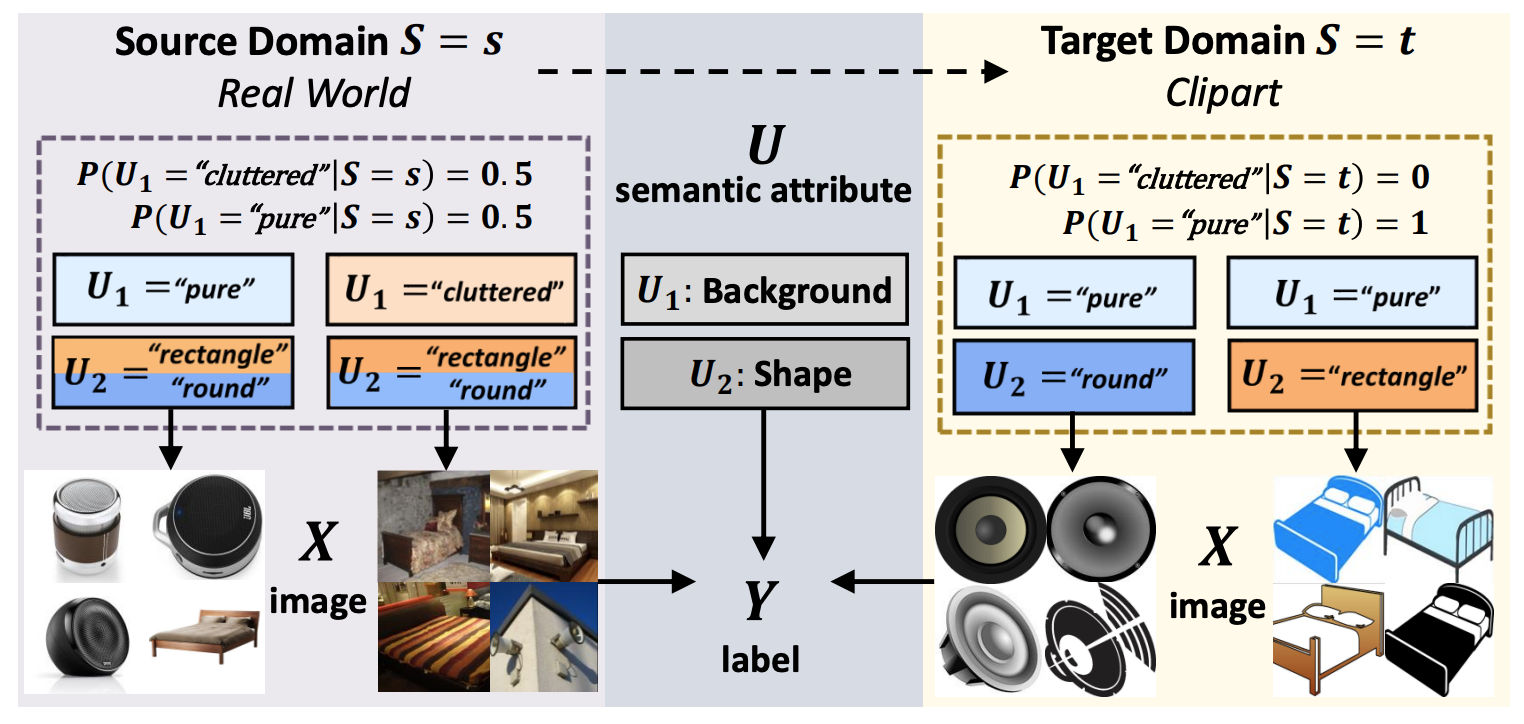
Transporting Causal Mechanisms for Unsupervised Domain Adaptation Zhongqi Yue, Qianru Sun, Xian-Sheng Hua, Hanwang Zhang International Conference on Computer Vision, ICCV '21. (Oral Presentation, 3%) [paper] [code] Existing Unsupervised Domain Adaptation (UDA) literature adopts the covariate shift and conditional shift assumptions, which essentially encourage models to learn common features across domains. However, due to the lack of supervision in the target domain, they suffer from the semantic loss: the feature will inevitably lose nondiscriminative semantics in source domain, which is however discriminative in target domain. We use a causal view—transportability theory —to identify that such loss is in fact a confounding effect, which can only be removed by causal intervention. However, the theoretical solution provided by transportability is far from practical for UDA, because it requires the stratification and representation of the unobserved confounder that is the cause of the domain gap. To this end, we propose a practical solution: Transporting Causal Mechanisms (TCM), to identify the confounder stratum and representations by using the domain-invariant disentangled causal mechanisms, which are discovered in an unsupervised fashion. |
|
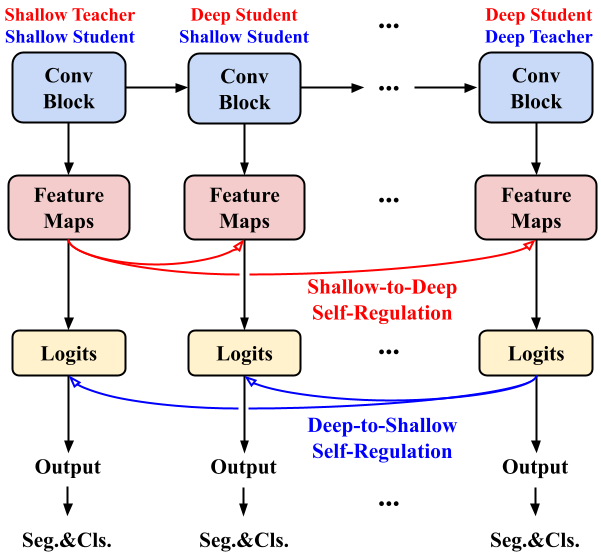
Self-Regulation for Semantic Segmentation Dong Zhang, Hanwang Zhang, Jinhui Tang, Xian-Sheng Hua, Qianru Sun International Conference on Computer Vision, ICCV '21. [paper] [code] In this paper, we seek reasons for the two major failure cases in Semantic Segmentation (SS): 1) missing small objects or minor object parts, and 2) mislabeling minor parts of large objects as wrong classes. We have an interesting finding that Failure-1 is due to the underuse of detailed features and Failure-2 is due to the underuse of visual contexts. To help the model learn a better trade-off, we introduce several Self-Regulation (SR) losses for training SS neural networks. By “self”, we mean that the losses are from the model per se without using any additional data or supervision. By applying the SR losses, the deep layer features are regulated by the shallow ones to preserve more details; meanwhile, shallow layer classification logits are regulated by the deep ones to capture more semantics. We conduct extensive experiments on both weakly and fully supervised SS tasks, and the results show that our approach consistently surpasses the baselines. |

|
A Large-Scale Benchmark for Food Image Segmentation Xiongwei Wu, Xin Fu, Ying Liu, Ee-Peng Lim, Steven C.H. Hoi, Qianru Sun The 29th ACM International Conference on Multimedia, ACM MM '21. (Main Track) [paper] [project] [challenge] Food image segmentation is a critical and indispensible task for developing health-related applications such as estimating food calories and nutrients. Existing food image segmentation models are underperforming due to two reasons: (1) there is a lack of high quality food image datasets with fine-grained ingredient labels and pixel-wise location masks -- the existing datasets either carry coarse ingredient labels or are small in size; and (2) the complex appearance of food makes it difficult to localize and recognize ingredients in food images, e.g., the ingredients may overlap one another in the same image, and the identical ingredient may appear distinctly in different food images. In this work, we build a new food image dataset FoodSeg103 (and its extension FoodSeg154) containing 9,490 images. We annotate these images with 154 ingredient classes and each image has an average of 6 ingredient labels and pixel-wise masks. In addition, we propose a multi-modality pre-training approach called ReLeM that explicitly equips a segmentation model with rich and semantic food knowledge. |
|
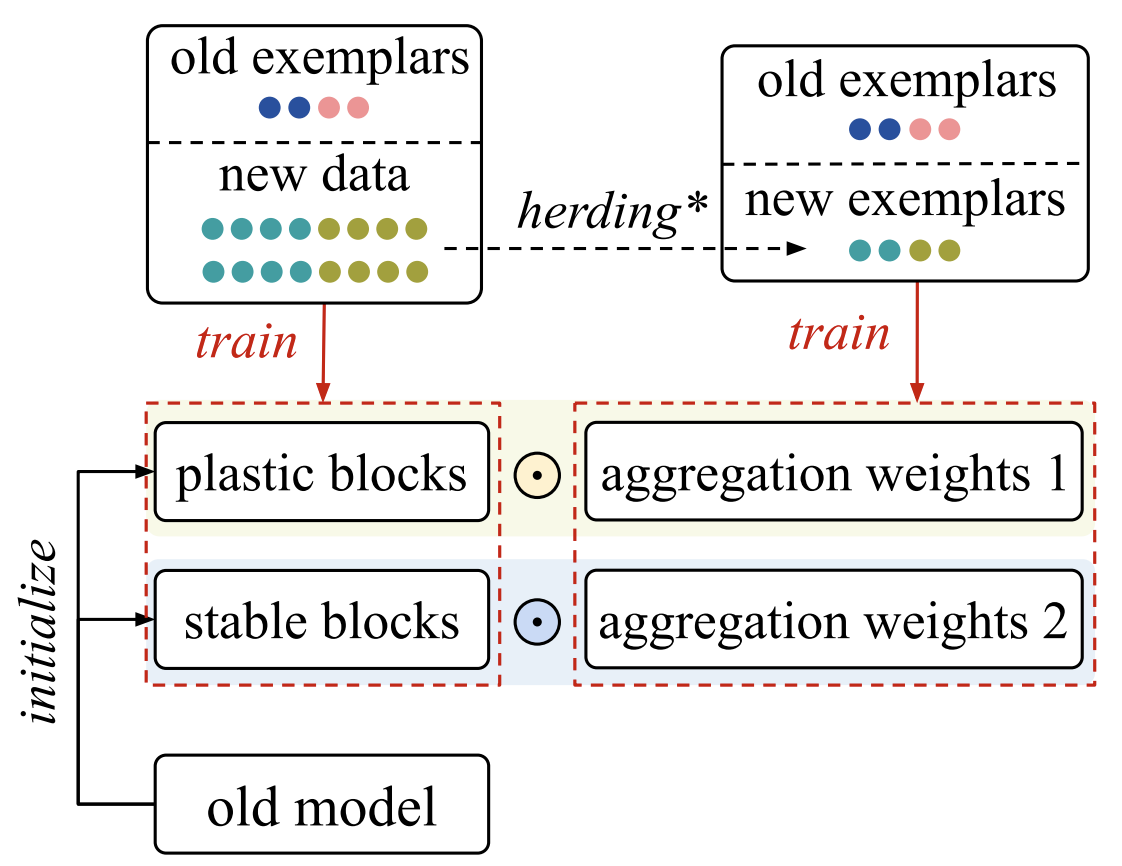
Adaptive Aggregation Networks for Class-Incremental Learning Yaoyao Liu, Bernt Schiele, Qianru Sun 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR '21. [paper] [supp] [code] Class-Incremental Learning (CIL) aims to learn a classification model with the number of classes increasing phase-by-phase. An inherent problem in CIL is the stability-plasticity dilemma between the learning of old and new classes, i.e., high-plasticity models easily forget old classes, but high-stability models are weak to learn new classes. We alleviate this issue by proposing a novel network architecture called Adaptive Aggregation Networks (AANets) in which we explicitly build two types of residual blocks at each residual level (taking ResNet as the baseline architecture): a stable block and a plastic block. We aggregate the output feature maps from these two blocks and then feed the results to the next-level blocks. We adapt the aggregation weights in order to balance these two types of blocks, i.e., to balance stability and plasticity, dynamically. |
|
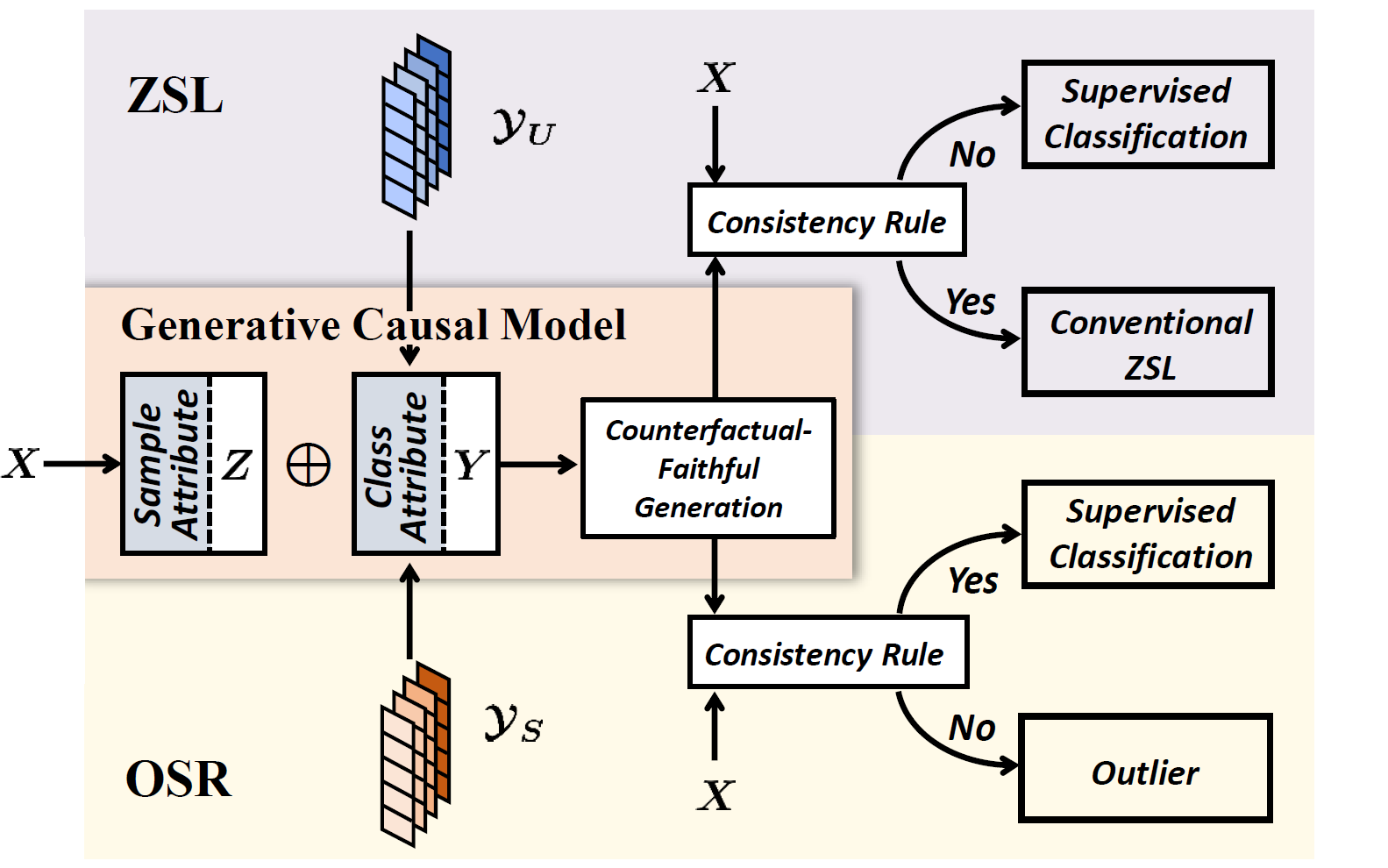
Counterfactual Zero-Shot and Open-Set Visual Recognition Zhongqi Yue, Tan Wang, Qianru Sun, Xian-Sheng Hua, Hanwang Zhang 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR '21. [paper] [supp] [code] We present a novel counterfactual framework for both Zero-Shot Learning and Open-Set Recognition, whose common challenge is generalizing to the unseen-classes by only training on the seen-classes. Our idea stems from the observation that the generated samples for unseen-classes are often out of the true distribution, which causes severe recognition rate imbalance between the seen-class (high) and unseen-class (low). We show that the key reason is that the generation is not Counterfactual Faithful, and thus we propose a faithful one, whose generation is from the sample-specific counterfactual question: What would the sample look like, if we set its class attribute to a certain class, while keeping its sample attribute unchanged? Thanks to the faithfulness, we can apply the Consistency Rule to perform unseen/seen binary classification, by asking: Would its counterfactual still look like itself? If "yes", the sample is from a certain class, and "no" otherwise. |
2020
|
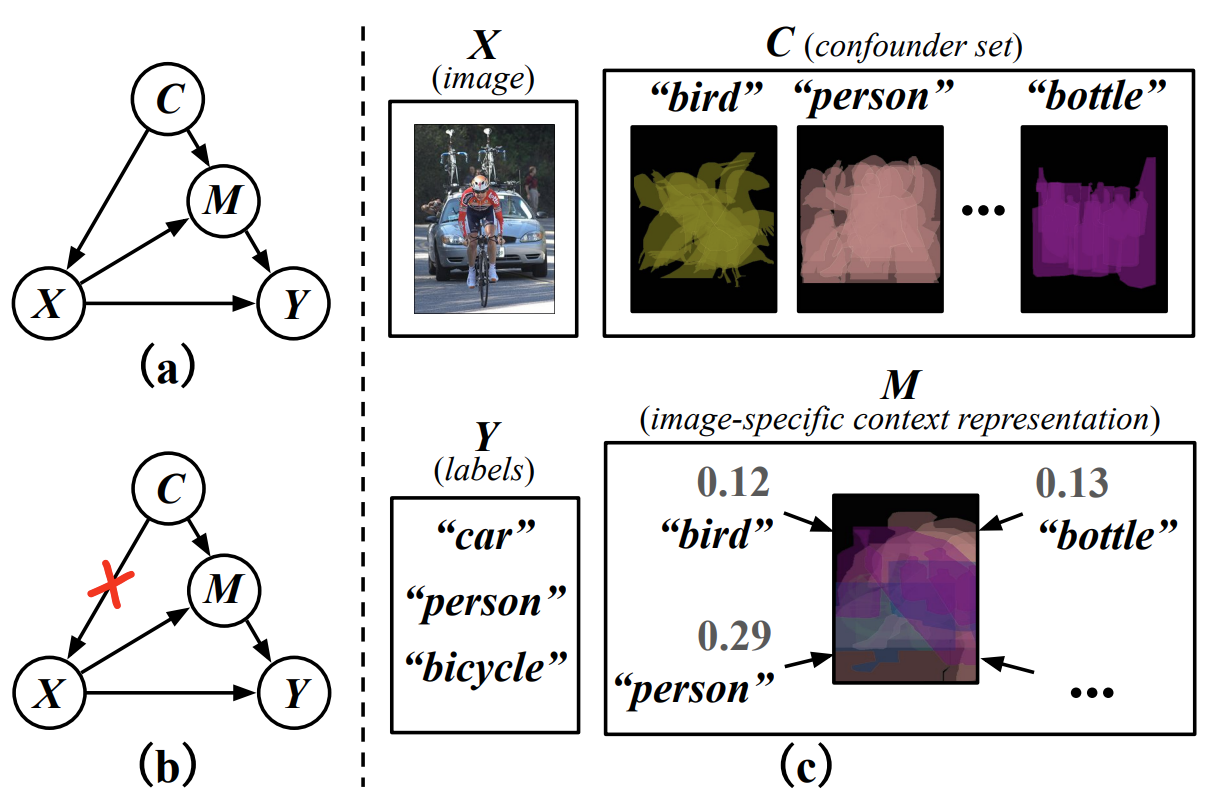
Causal Intervention for Weakly-Supervised Semantic Segmentation Dong Zhang, Hanwang Zhang, Jinhui Tang, Xian-Sheng Hua, Qianru Sun Neural Information Processing Systems, NeurIPS '20. (Oral Presentation, 1.1%) [paper] [code] We present a causal inference framework to improve Weakly-Supervised Semantic Segmentation (WSSS). Specifically, we aim to generate better pixel-level pseudo-masks by using only image-level labels -- the most crucial step in WSSS. We attribute the cause of the ambiguous boundaries of pseudo-masks to the confounding context, e.g., the correct image-level classification of "horse" and "person" may be not only due to the recognition of each instance, but also their co-occurrence context, making the model inspection (e.g., CAM) hard to distinguish between the boundaries. Inspired by this, we propose a structural causal model to analyze the causalities among images, contexts, and class labels. Based on it, we develop a new method: Context Adjustment (CONTA), to remove the confounding bias in image-level classification and thus provide better pseudo-masks as ground-truth for the subsequent segmentation model. |

|
Interventional Few-Shot Learning Zhongqi Yue, Hanwang Zhang, Qianru Sun, Xian-Sheng Hua Neural Information Processing Systems, NeurIPS '20. [paper] [code] We uncover an ever-overlooked deficiency in the prevailing Few-Shot Learning (FSL) methods: the pre-trained knowledge is indeed a confounder that limits the performance. This finding is rooted from our causal assumption: a Structural Causal Model (SCM) for the causalities among the pre-trained knowledge, sample features, and labels. Thanks to it, we propose a novel FSL paradigm: Interventional FewShot Learning (IFSL). Specifically, we develop three effective IFSL algorithmic implementations based on the backdoor adjustment, which is essentially a causal intervention towards the SCM of many-shot learning: the upper-bound of FSL in a causal view. It is worth noting that the contribution of IFSL is orthogonal to existing fine-tuning and meta-learning based FSL methods, hence IFSL can improve all of them, achieving a new 1-/5-shot state-of-the-art. |
|
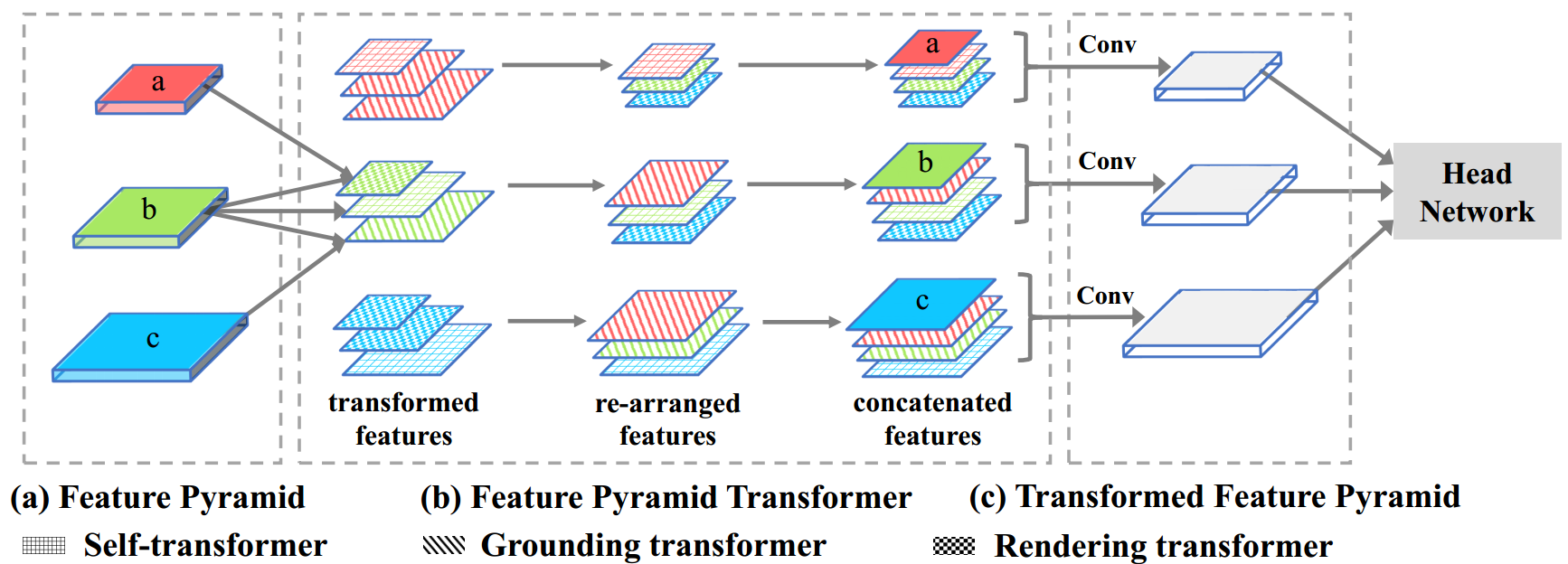
Feature Pyramid Transformer Dong Zhang, Hanwang Zhang, Jinhui Tang, Meng Wang, Xian-Sheng Hua, Qianru Sun European Conference on Computer Vision, ECCV '20. [paper] [code] Feature interactions across space and scales underpin modern visual recognition systems because they introduce beneficial visual contexts. Conventionally, spatial contexts are passively hidden in the CNN's increasing receptive fields or actively encoded by non-local convolution. Yet, the non-local spatial interactions are not across scales, and thus they fail to capture the non-local contexts of objects (or parts) residing in different scales. To this end, we propose a fully active feature interaction across both space and scales, called Feature Pyramid Transformer. It transforms any feature pyramid into another feature pyramid of the same size but with richer contexts, by using three specially designed transformers in self-level, top-down, and bottom-up interaction fashion. FPT serves as a generic visual backbone with fair computational overhead. |
|
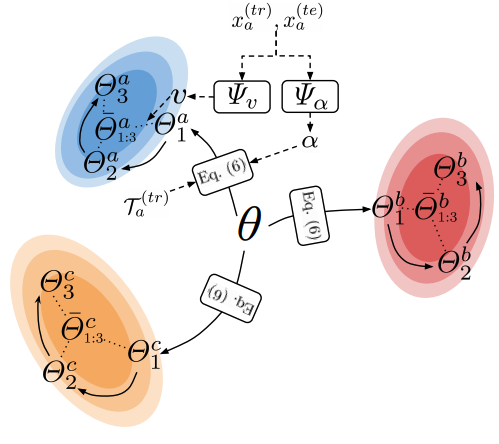
An Ensemble of Epoch-wise Empirical Bayes for Few-shot Learning Yaoyao Liu, Bernt Schiele, Qianru Sun European Conference on Computer Vision, ECCV '20. [paper] [code] Few-shot learning aims to train efficient predictive models with a few examples. The lack of training data leads to poor models that perform high-variance or low-confidence predictions. In this paper, we propose to meta-learn the ensemble of epoch-wise empirical Bayes models (E3BM) to achieve robust predictions. "Epoch-wise" means that each training epoch has a Bayes model whose parameters are specifically learned and deployed. "Empirical" means that the hyperparameters, e.g., used for learning and ensembling the epoch-wise models, are generated by hyperprior learners conditional on task-specific data. We introduce four kinds of hyperprior learners by considering inductive vs. transductive, and epoch-dependent vs. epoch-independent, in the paradigm of meta-learning. Our ablation study shows that both "epoch-wise ensemble" and "empirical" encourage high efficiency and robustness in the model performance. |
|
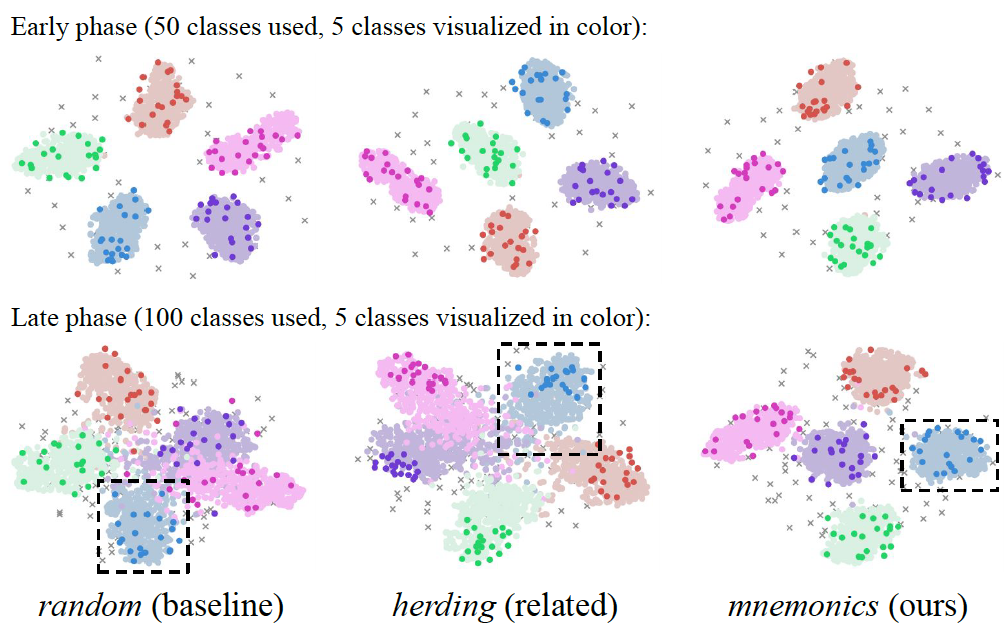
Mnemonics Training: Multi-Class Incremental Learning without Forgetting Yaoyao Liu, Yuting Su, An-An Liu, Bernt Schiele, Qianru Sun The 33rd Conference on Computer Vision and Pattern Recognition, CVPR '20. (Oral Presentation, 4%) [paper] [supp.] [video] [code] Multi-Class Incremental Learning aims to learn new concepts by incrementally updating a model trained on previous concepts. However, there is an inherent trade-off to effectively learning new concepts without catastrophic forgetting of previous ones. To alleviate this issue, it has been proposed to keep around a few examples of the previous concepts but the effectiveness of this approach heavily depends on the representativeness of these examples. This paper proposes a novel and automatic framework we call mnemonics, where we parameterize exemplars and make them optimizable in an end-to-end manner. We train the framework through bilevel optimizations, i.e., model-level and exemplar-level. We conduct extensive experiments on three MCIL benchmarks. Interestingly and quite intriguingly, the mnemonics exemplars tend to be on the boundaries between classes. |
|
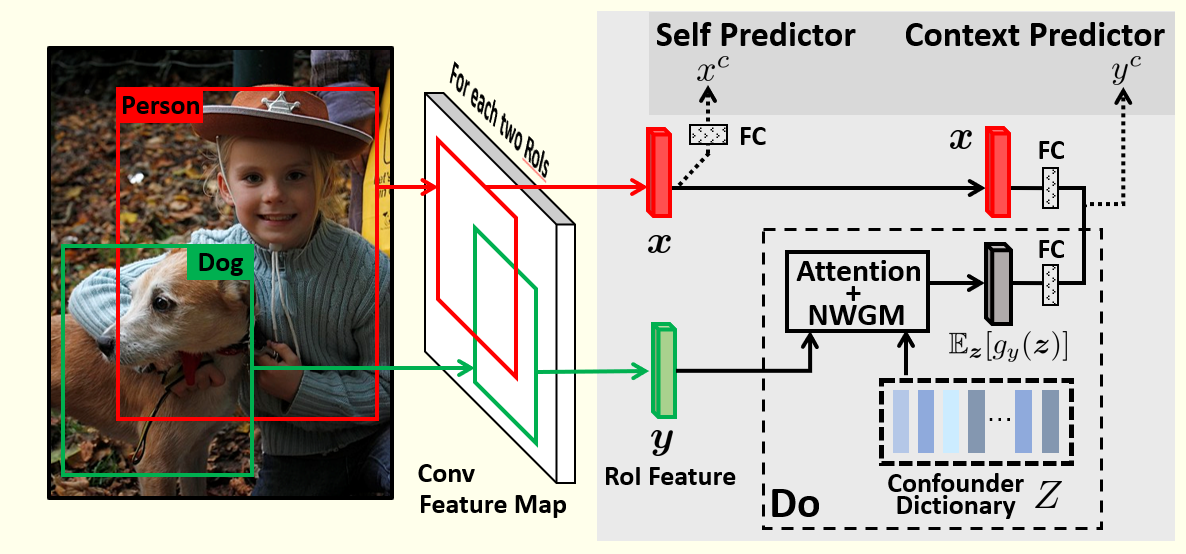
Visual Commonsense R-CNN Tan Wang, Jianqiang Huang, Hanwang Zhang, Qianru Sun The 33rd Conference on Computer Vision and Pattern Recognition, CVPR '20. [paper] [supp.] [video] [code] We present a novel unsupervised feature representation learning method, Visual Commonsense Region-based Convolutional Neural Network (VC R-CNN), to serve as an improved visual region encoder for high-level tasks such as captioning and VQA. Given a set of detected object regions in an image (e.g., by Faster R-CNN), like any other unsupervised feature learning methods (e.g., word2vec), the proxy training objective of VC R-CNN is to predict the contextual objects of a region. However, they are fundamentally different: the prediction of VC R-CNN is by causal intervention: P(Y|do(X)), while others are by the conventional likelihood: P(Y|X). This is also the core reason why VC R-CNN can learn ``sense-making'' knowledge --- like "chair" can be sat --- while not just common co-occurrences --- "chair" is likely to exist if "table" is observed. |
2019
|
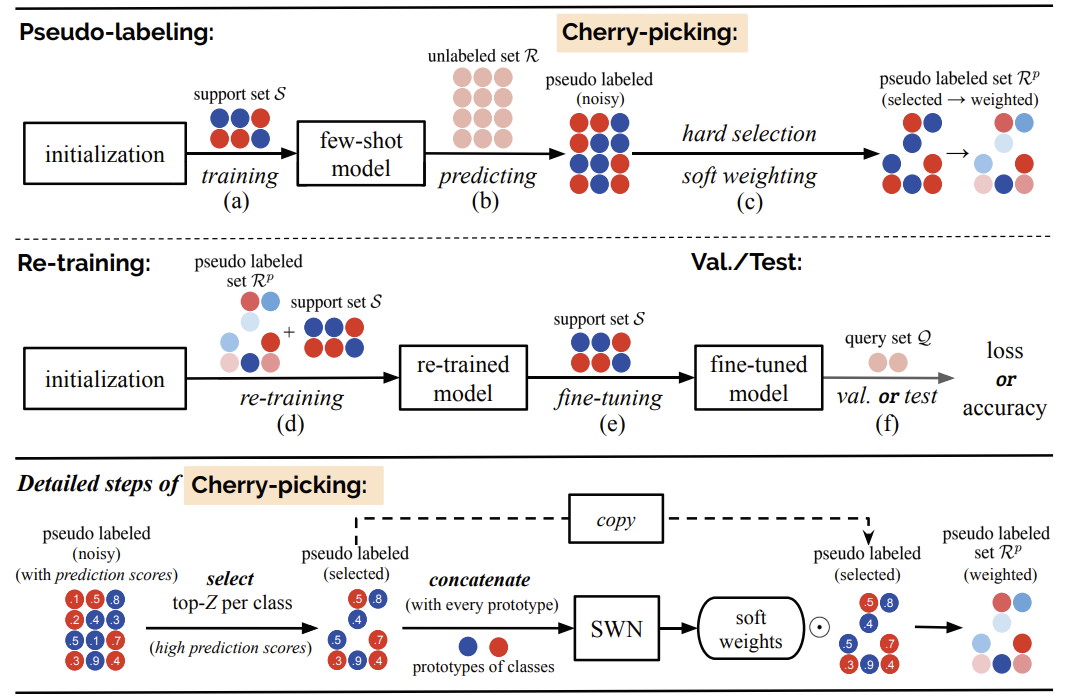
Learning to Self-Train for Semi-Supervised Few-Shot Classification Xinzhe Li, Qianru Sun, Yaoyao Liu, Shibao Zheng, Tat-Seng Chua, Bernt Schiele The 33rd Annual Conference on Neural Information Processing Systems, NeurIPS'19. [paper] [slides] [poster] [code] Few-shot classification (FSC) is challenging due to the scarcity of labeled training data (e.g. only one labeled data point per class). Meta-learning has shown to achieve promising results by learning to initialize a classification model for FSC. In this paper we propose a novel semi-supervised meta-learning method called learning to self-train (LST) that leverages unlabeled data and specifically meta-learns how to cherry-pick and label such unsupervised data to further improve performance. To this end, we train the LST model through a large number of semi-supervised few-shot tasks. On each task, we train a few-shot model to predict pseudo labels for unlabeled data, and then iterate the self-training steps on labeled and pseudo-labeled data with each step followed by fine-tuning. We additionally learn a soft weighting network (SWN) to optimize the self-training weights of pseudo labels so that better ones can contribute more to gradient descent optimization. |
|
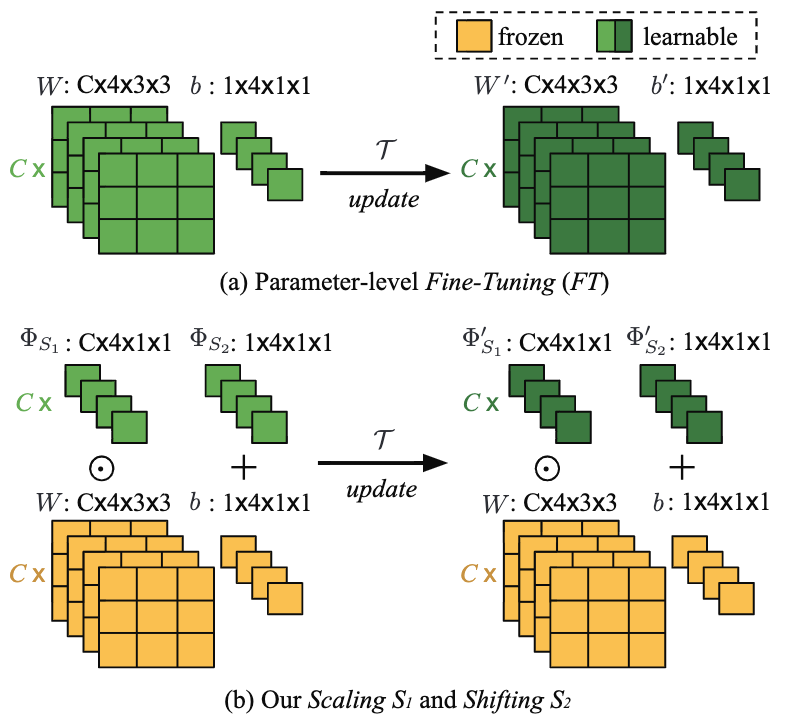
Meta-Transfer Learning for Few-Shot Learning Qianru Sun, Yaoyao Liu, Tat-Seng Chua, Bernt Schiele The 32nd Conference on Computer Vision and Pattern Recognition, CVPR'19. Top 200 Most Cited CVPR Paper over the Last Five Years [paper] [poster] [code] Meta-learning has been proposed as a framework to address the challenging few-shot learning setting. The key idea is to leverage a large number of similar few-shot tasks in order to learn how to adapt a base-learner to a new task for which only a few labeled samples are available. As deep neural networks (DNNs) tend to overfit using a few samples only, meta-learning typically uses shallow neural networks (SNNs), thus limiting its effectiveness. In this paper we propose a novel few-shot learning method called meta-transfer learning (MTL) which learns to adapt a deep NN for few shot learning tasks. Specifically, meta refers to training multiple tasks, and transfer is achieved by learning scaling and shifting functions of DNN weights for each task. In addition, we introduce the hard task (HT) meta-batch scheme as an effective learning curriculum for MTL. |
2018
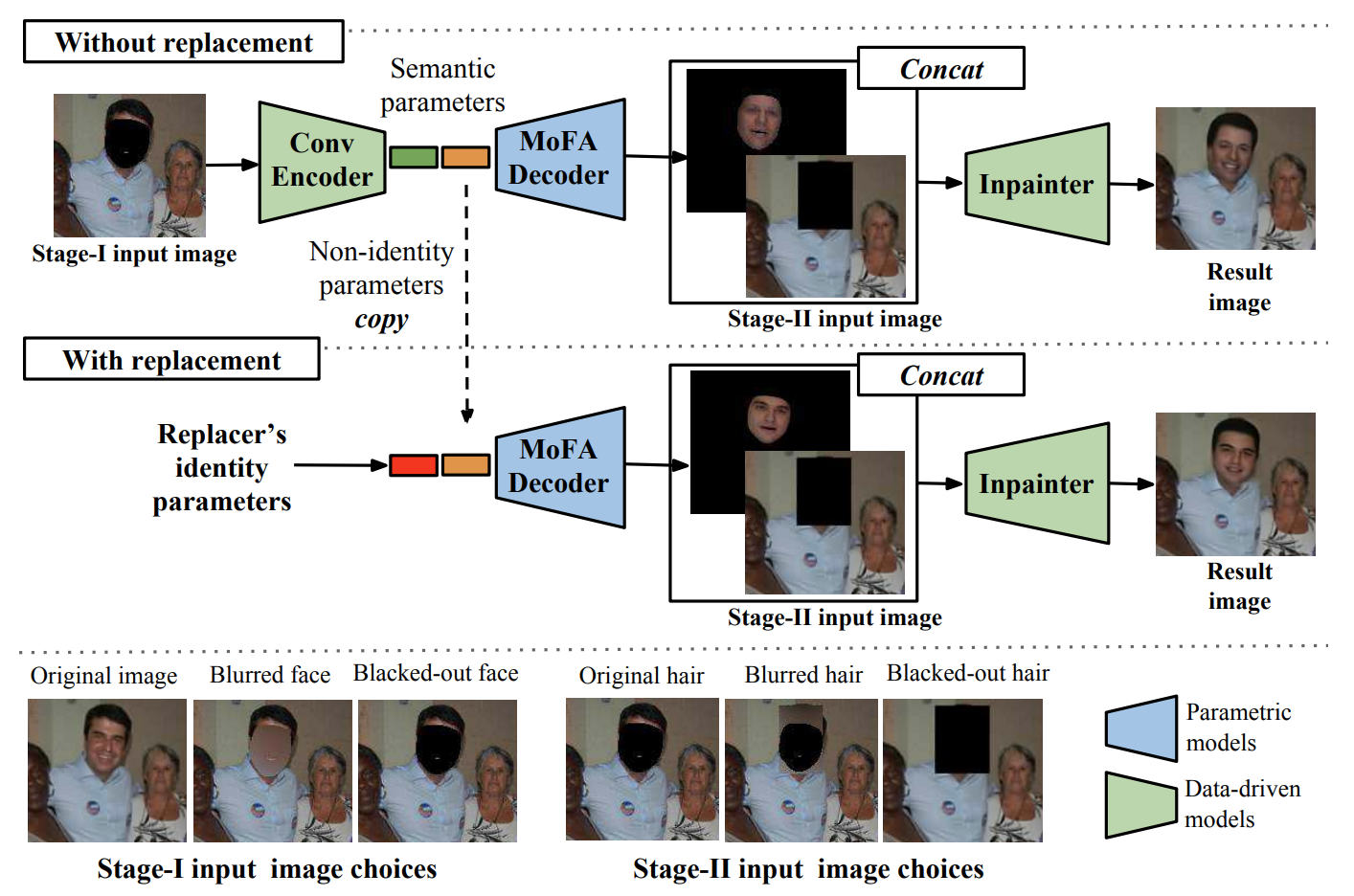
|
A Hybrid Model for Identity Obfuscation by Face Replacement Qianru Sun, Ayush Tewari, Weipeng Xu, Mario Fritz, Christian Theobalt, Bernt Schiele The 15th European Conference on Computer Vision, ECCV'18. [paper] [decoder code] As more and more personal photos are shared and tagged in social media, avoiding privacy risks such as unintended recognition, becomes increasingly challenging. We propose a new hybrid approach to obfuscate identities in photos by head replacement. Our approach combines state of the art parametric face synthesis with latest advances in Generative Adversarial Networks (GAN) for data-driven image synthesis. On the one hand, the parametric part of our method gives us control over the facial parameters and allows for explicit manipulation of the identity. On the other hand, the data-driven aspects allow for adding fine details and overall realism as well as seamless blending into the scene context. In our experiments we show highly realistic output of our system that improves over the previous state of the art in obfuscation rate while preserving a higher similarity to the original image content. |
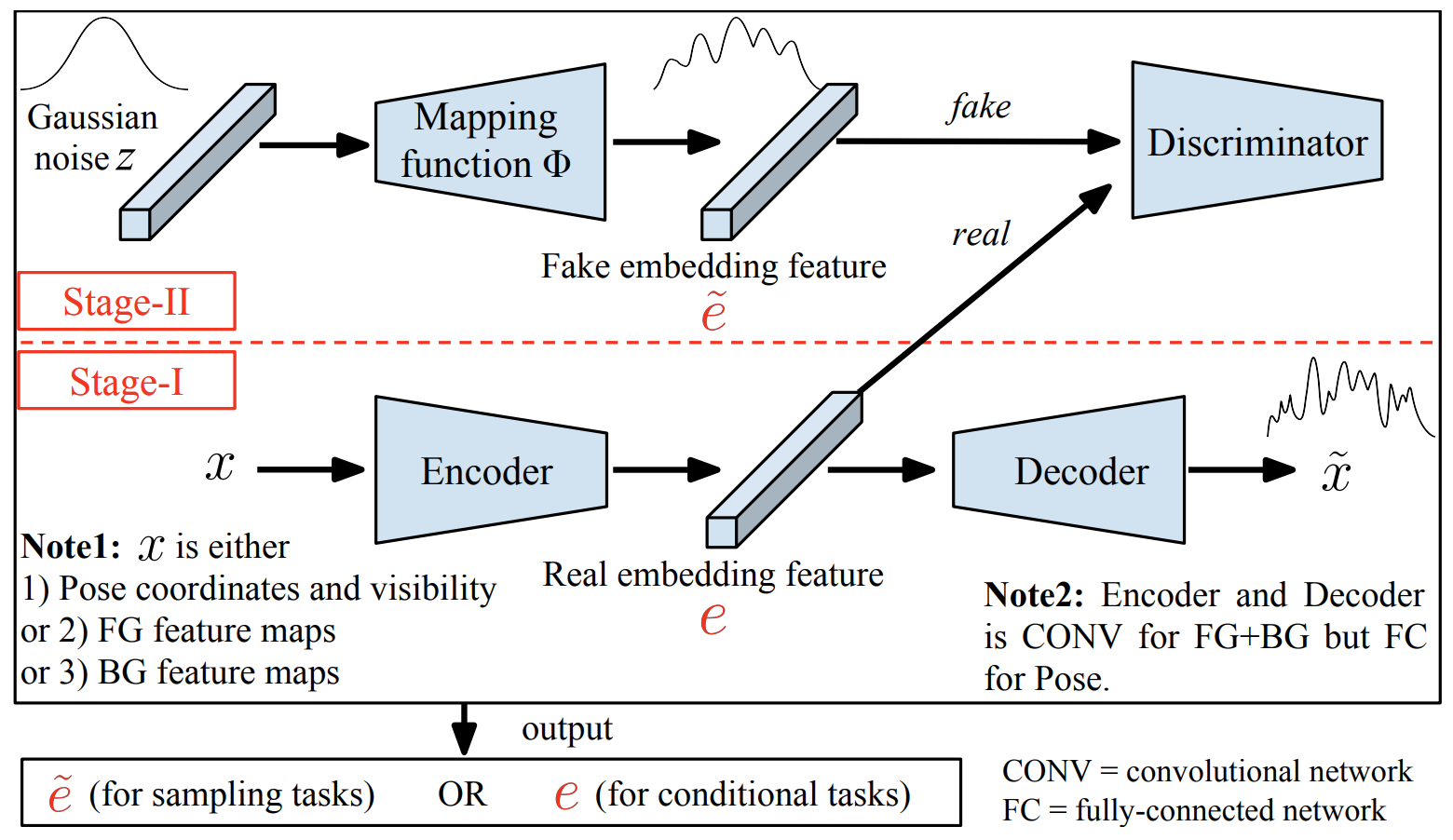
|
Disentangled Person Image Generation Liqian Ma, Qianru Sun, Stamatios Georgoulis, Luc Van Gool, Bernt Schiele, Mario Fritz 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR'18. (Spotlight Presentation) [paper] [code] [project] Generating novel, yet realistic, images of persons is a challenging task due to the complex interplay between the different image factors, such as the foreground, background and pose information. In this work, we aim at generating such images based on a novel, two-stage reconstruction pipeline that learns a disentangled representation of the aforementioned image factors and generates novel person images at the same time. First, a multi-branched reconstruction network is proposed to disentangle and encode the three factors into embedding features, which are then combined to re-compose the input image itself. Second, three corresponding mapping functions are learned in an adversarial manner in order to map Gaussian noise to the learned embedding feature space, for each factor, respectively. Using the proposed framework, we can manipulate the foreground, background and pose of the input image, and also sample new embedding features to generate such targeted manipulations, that provide more control over the generation process. Experiments on the Market-1501 and Deepfashion datasets show that our model does not only generate realistic person images with new foregrounds, backgrounds and poses, but also manipulates the generated factors and interpolates the in-between states. Another set of experiments on Market-1501 shows that our model can also be beneficial for the person re-identification task. |
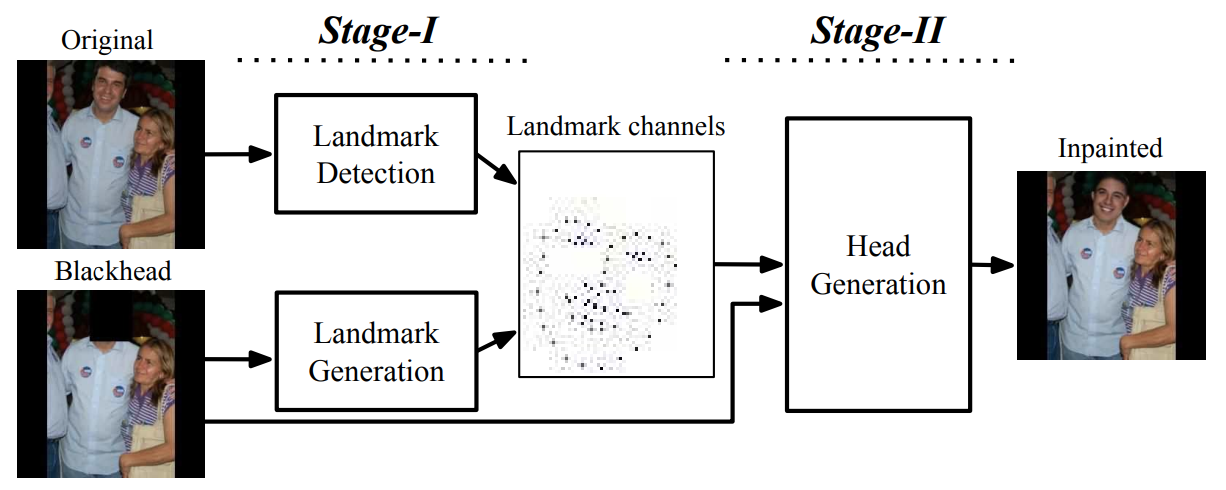
|
Natural and Effective Obfuscation by Head Inpainting Qianru Sun, Liqian Ma, Seong Joon Oh, Luc Van Gool, Bernt Schiele, Mario Fritz 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR'18. [paper] [decoder code] [PDM code] As more and more personal photos are shared online, being able to obfuscate identities in such photos is becoming a necessity for privacy protection. People have largely resorted to blacking out or blurring head regions, but they result in poor user experience while being surprisingly ineffective against state of the art person recognizers. In this work, we propose a novel head inpainting obfuscation technique. Generating a realistic head inpainting in social media photos is challenging because subjects appear in diverse activities and head orientations. We thus split the task into two sub-tasks: (1) facial landmark generation from image context (e.g. body pose) for seamless hypothesis of sensible head pose, and (2) facial landmark conditioned head inpainting. We verify that our inpainting method generates realistic person images, while achieving superior obfuscation performance against automatic person recognizers. |
2017
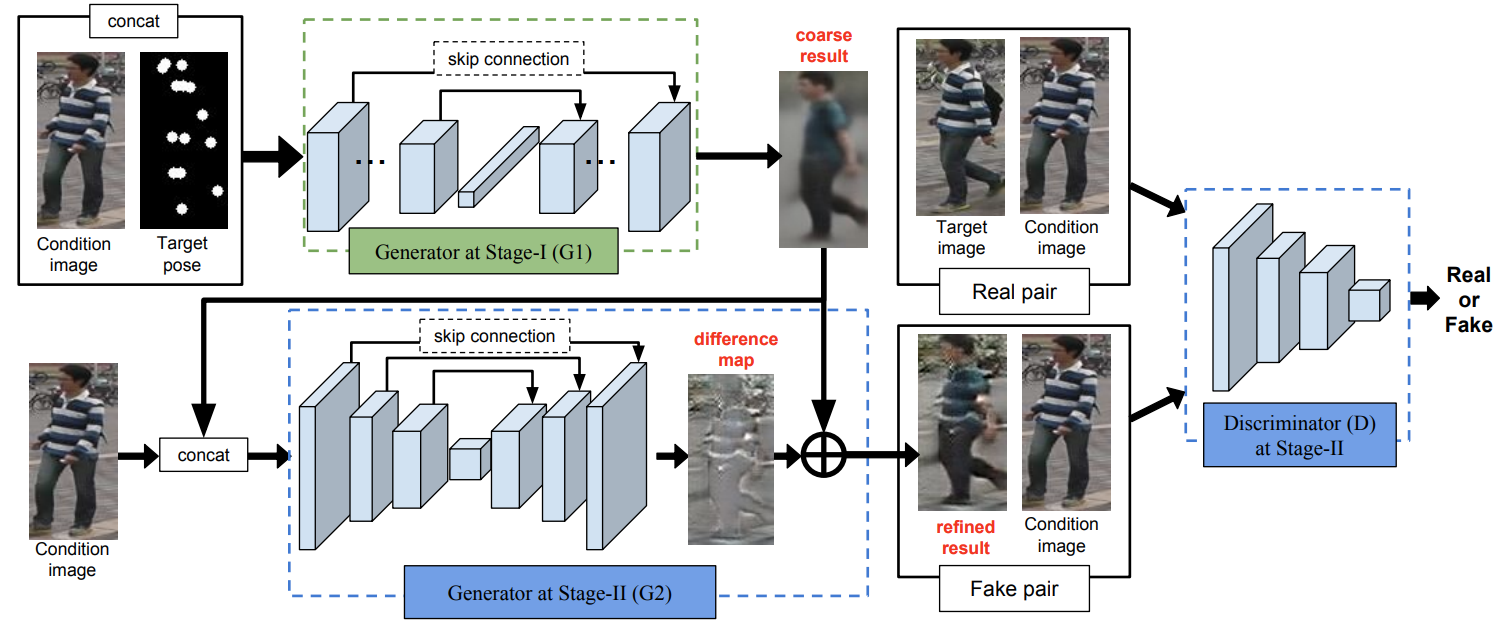
|
Pose Guided Person Image Generation Liqian Ma, Xu Jia, Qianru Sun, Bernt Schiele, Tinne Tuytelaars, Luc Van Gool The 31st Annual Conference on Neural Information Processing, NIPS'17. Top 100 Most Cited NIPS (NeurIPS) Paper over the Last Five Years [paper] [slides] [code] This paper proposes the novel Pose Guided Person Generation Network (PG2) that allows to synthesize person images in arbitrary poses, based on an image of that person and a novel pose. Our generation framework PG2 utilizes the pose information explicitly and consists of two key stages: pose integration and image refinement. In the first stage the condition image and the target pose are fed into a U-Net-like network to generate an initial but coarse image of the person with the target pose. The second stage then refines the initial and blurry result by training a U-Net-like generator in an adversarial way. Extensive experimental results on both 128×64 re-identification images and 256×256 fashion photos show that our model generates high-quality person images with convincing details. |
|
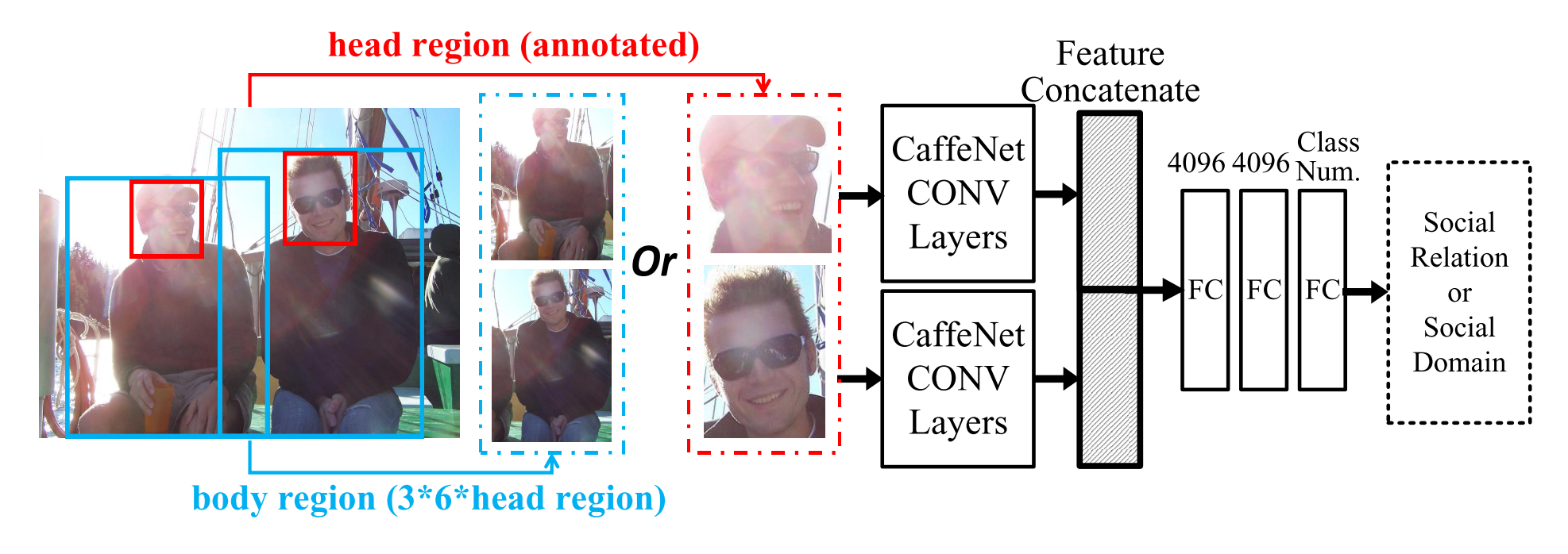
A Domain Based Approach to Social Relation Recognition Qianru Sun, Bernt Schiele, Mario Fritz 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR'17. [paper] [code] [project] Social relations are the foundation of human daily life. Developing techniques to analyze such relations from visual data bears great potential to build machines that better understand us and are capable of interacting with us at a social level. Previous investigations have remained partial due to the overwhelming diversity and complexity of the topic and consequently have only focused on a handful of social relations. In this paper, we argue that the domain-based theory from social psychology is a great starting point to systematically approach this problem. The theory provides coverage of all aspects of social relations and equally is concrete and predictive about the visual attributes and behaviors defining the relations included in each domain. We provide the first dataset built on this holistic conceptualization of social life that is composed of a hierarchical label space of social domains and social relations. We also contribute the first models to recognize such domains and relations and find superior performance for attribute based features. Beyond the encouraging performance of the attribute based approach, we also find interpretable features that are in accordance with the predictions from social psychology literature. Beyond our findings, we believe that our contributions more tightly interleave visual recognition and social psychology theory that has the potential to complement the theoretical work in the area with empirical and data-driven models of social life. |